

If you've read about ChatGPT or tried out yourself, you'll have the following question: “How can I utilize this?”
Many people are already using the ChatGPT website instead of the search engine. Some companies have already linked ChatGPT to launch products. You can tell by looking at the trending keyword on Product Hunt.
What does it mean to “use” ChatGPT into a product? And what do you need to consider? Will ChatGPT become a world-changing invention like the steam engine?
In this article, I want to talk about the difficulty of productionizing ChatGPT (a.k.a. Taming the monster).
This post is also posted in Korean.
How ChatGPT can be linked to your product
The first way to access ChatGPT is through the UI. But you can't use this method if you want to link it to your product. Asking users to open a new browser tab and to access OpenAI is not good for UX. Also, you can't get any data because user interaction happens outside of your product.
For example, let's say I am writing a Regular Expression (regex) (by the way, ChatGPT is quite good at this). I usually have to write Regex in my Code Editor.I'd turn on my browser and ask questions on the ChatGPT UI.
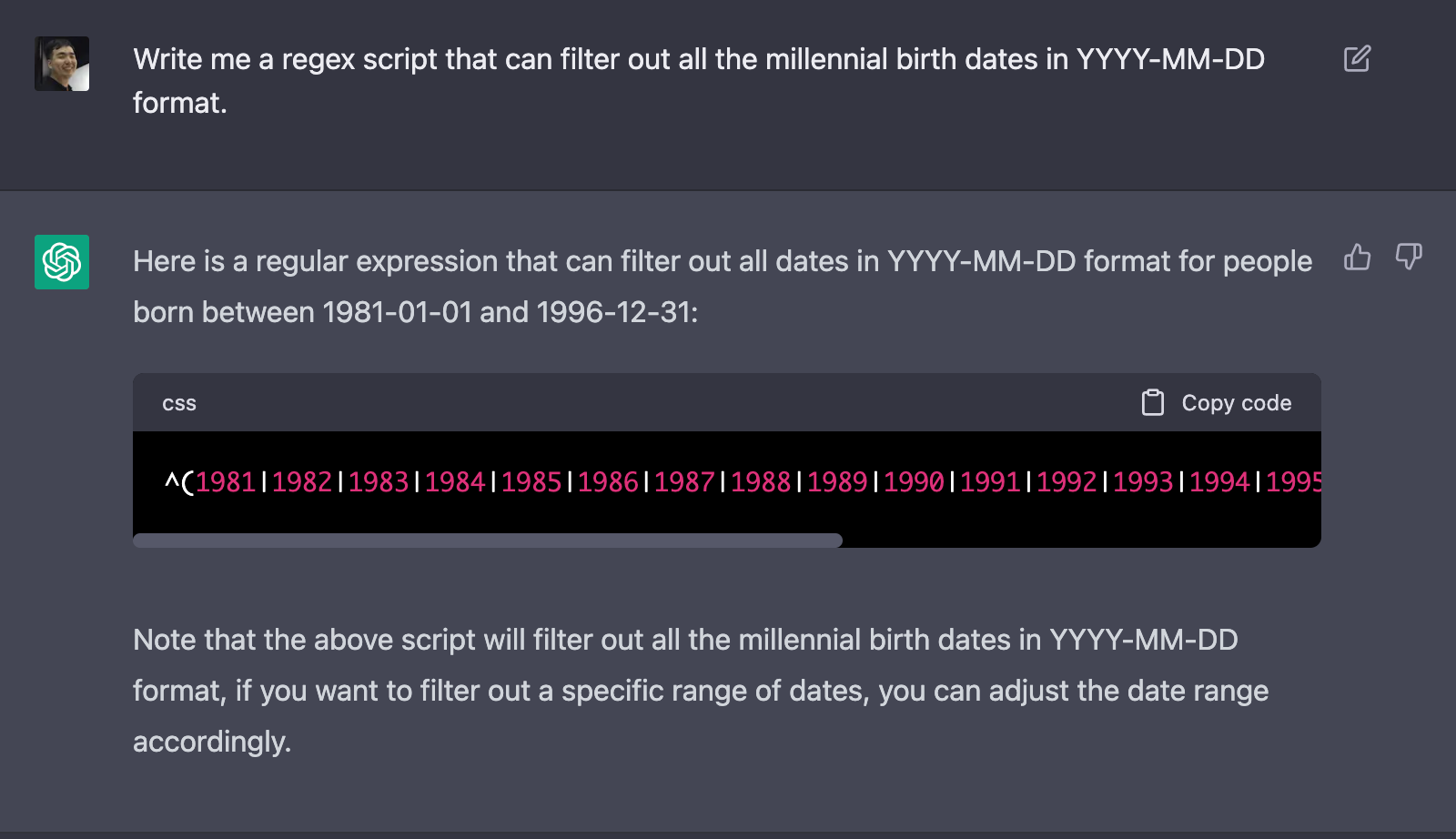
The results from this need to be copy & pasted again into my code editor. While it's not horrible, wouldn't it be easier and faster if I could get the results right away from the editor?
If so, you need to create an Editor Extension application, and eventually leverage the API of ChatGPT.
What is API(Application Programming Interface)?
API is a method that enables communication through information exchange between applications. Think of it as a function (Input => Output method), but between different applications.
The simplest API is to retrieve a portion of the data from a database. For example, you can get today's weather information from the Meteorological Agency open API.
The user of the API usually doesn't need to know what programs, servers, and databases are behind it. Some APIs have complex server logic, but users can only receive output based on the input they provided. This has a great advantage for the owner of the API, because information can be provided only as part of the API output, without exposing the contents of the code they built to the user.
APIs of OpenAI
ChatGPT is available through an API, same as if you ask a question in ChatGPT in OpenAI UI. The UI is just an outer packaging that lets you communicate easily with their models. The messages entered in the UI are sent to OpenAI's models through the API, anyways.
ChatGPT API is available to anyone who registers (and pays). By writing some code, you can create a product that exchanges questions and answers with ChatGPT. You can build ChatGPT-based Slack, Whatsapp Chatbot, etc. this way.
OpenAI's product strategy is to “API-ify” huge ML models (e.g. ChatGPT, GPT-3, DALL-E, Embedding, etc.) developed in their research lab and to release them to the world. And the revenue strategy is to do a charge-per-call*.
* Starting as non-profit and turning to for-profit org, OpenAI is often criticized as being really "Open".
OpenAI's API is simple. The input is model type, input, temperature to control randomness, max_tokens.
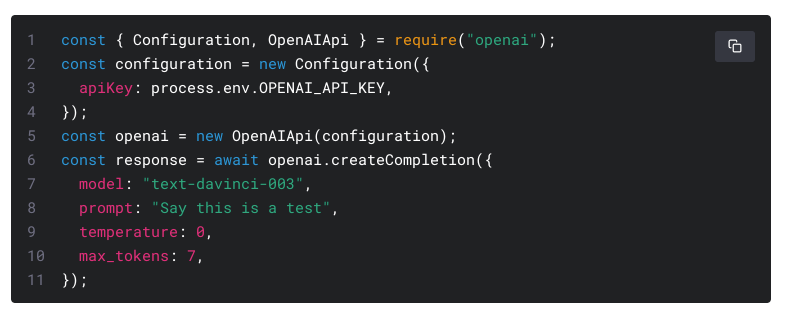
Pretty easy, right?
However, it takes a lot more consideration to create a product using this simple but powerful API.
There are many things to consider when creating a product based on any ML model as well as ChatGPT.
- Measuring model performance,
- Sensitivity to model errors,
- Model improvement / error correction,
- Stability of the model prediction/generation,
- Model Speed,
- Legal responsibilities.
I'll cover them one by one.
1. How to measure ML model performance
Performance must be measured before all ML models are used. If you are using a model that you've trained and built, it's common to take part of the data you have and use it as an evaluation set.
The problem is when you use a model provided by another company, such as OpenAI, through an API. In this case, the evaluation set becomes even more important. This is because there is a high probability that the data learned by the API model and the data entering your product are different.
Of course, giant language models like GPT claim to show high "generalization" because they have been learned from such vast amounts of data that they have seen all text types around the world, but it is important to check them because performance may highly depend on types of product, field, and language of your users.
That's why you need to build an evaluation set for your product. Or it's like going forward blindfolded. OpenAI also emphasizes the importance of having evaluation sets.
However, building your own systems that build, label, set metrics, and automatically evaluate these datasets on a regular basis is not easy, both in terms of cost and engineering difficulty. That's why standard benchmark evaluation sets are jointly created by several research institutes.
2. How sensitive are you to errors?
Next, you should consider how sensitive the product is from the errors of ML models. If you are using a text-generating model like ChatGPT, most likely, you will be very sensitive, especially if the product is showing the generated output to the user directly. There are many cases that AI-based chatbots can put you in a media backlash and shutdown of the product, if you don't do it well. Even with 99% accuracy in the evaluation set, one or two mistakes can ruin the whole picture. That's why companies like Google “were” careful to address safety issues for text generation models like LaMDA.
Although ChatGPT claims to filter results based on its own safety models and provides a basic Moderation API, the policy clearly states that it puts the legal responsibility to the users if any problems were to arise.
If there is a process where humans can examine or modify the model output, there is a little more room. For example, I think that the workflow of ChatGPT drafting some texts, then reviewed and modified by humans can achieve a significant productivity increase. Recently, it seems that such products are being released in Korea already like Wrtn.ai (based on Hyper Clova LLM).
For example, documents that need to be written to submit to government offices have a fixed format and structure. This is a perfect use case, as nobody loves reading and writing these kinds of text. Even if you get a silly or unsafe answer, you can just regenerate or modify some parts of it.
3. How to improve the model / correct errors
Let's say you've successfully built a dataset for evaluation and even measured the performance of ChatGPT. It will probably not be 100% performance. So what should you do now?
This can be divided into two parts: (a) overall model improvement, and (b) error individual correction.
(a) Overall model improvement
If you create a product based on ChatGPT, it is impossible to improve the way you “change” the ML model. Because the model doesn't change unless OpenAI updates it. You do not have ownership. Therefore, there is only one thing that can be done. Changing the Input Prompt. This is also known as Prompt Engineering.
When GPT-3 first came out to the world, it presented a paradigm shift in NLP in that it became possible to explain and illustrate the problem you want to solve in natural language to the ML model directly, without any coding or data addition.
This flexibility was groundbreaking because even non-experts can "control" ML models, but the problem is that "control" is not trivial. It's like configuring a black box and pressing this and that, looking at the results and finding out what is working or not. Most of the time, it's not intuitive and time-consuming. If you switch one thing it may work well for one example, but does not work for another.
**Can't I use the Finetune method? (advanced)
Finetune is a way to improve performance by training an already pre-trained model on additional datasets that are smaller but fit specific tasks. OpenAI offers Finetuning as Beta, but not yet available for ChatGPT.
This may be the most obvious, best way to improve a model. OpenAI also seems to have finetuned intensively by collecting additional data through crowd workers in places, where labor is cheaper, to make ChatGPT perform better on certain kinds of problems.
But the problem is that collecting data for finetuning is a very costly and time-consuming task for a product development team. OpenAI also needs to host and serve each finetuned model separately (it is not general-purpose anymore), but we don't know if they can create a system that makes economic sense at the model scale of ChatGPT.
(b) Error Individual Calibration
As I mentioned above, even if the model is 99% correct, an error on 1-2 answers can be an obstacle for product launch. What should you do if the model generates wrong facts in a question that users often ask?
For example, what to do when you created a Q&A chatbot about an important event, but it keeps saying the date or place of the event incorrectly? What if the customer center chatbot makes up a product return process that your company has no ideas about? What if a conversational chatbot talks well, then spits out negative, inappropriate answers for one sensitive topic?
These individual error corrections are a real challenge when using generative models like ChatGPT. There's no process to ensure OpenAI will fix it. It is just a thumbs up/down on the GUI, which may be included in the next training data, so it might be fixed in the next update, but nothing is guaranteed.
Without having the ownership of the model, it is difficult to correct individual errors on your side. It may be necessary to analyze the input and output of ChatGPT in a separate system on your end.
Maybe, Frequently asked questions (FAQs) can be answered in an answer pool that already exists, rather than going through ChatGPT. Or additional information from your system may need to be appended to the input that goes into the ChatGPT. There is no one-fix-everything answer.
4. How do you ensure the stability of your answers?
The way to order sandwiches in SUBWAY is quite difficult for first-time visitors. There are many things to choose, from bread to sauce. But if you visit a few times, you get used to it because the same pattern repeats. But imagine how confusing and irritating it would be if the order and type of questions asked change every time you go.
Similarly, it would be very confusing if the product’s response to the same thing you said is different every time. A smart speaker understands you properly every day when you say "turn on the light in the room" and suddenly ask you back one day, "Which room do you want me to turn on?" You will be puzzled.
The problem is that when OpenAI updates the ChatGPT model, it can have a large influence on your product use case. The influence may be positive, but it might not be. It is not easy for the product development team to have control over this change as OpenAI is the model owner.
OpenAI will probably pour in additional data and re-learned it based on their analysis of their users, not yours. While most products may benefit from this change, they can harm some. All OpenAI models, especially large language models like ChatGPT, are trained to be one “general purpose” to support all use cases. Since ChatGPT cannot reflect the latest information without retraining, periodic model update is inevitable.
**My evaluation set still shows good results. Then isn’t it fine? (advanced)
If you have an evaluation set, you can re-evaluate each time the ChatGPT model is updated. This is already a great start to ensure stability.
However, let's think about the case where the performance has not changed in the evaluation set.
Although the change in overall performance is zero, the change that users feel may not be zero. For example, let's say that 90 out of 100 data before the update is correct and 10 are wrong, so it has 90% performance. What if 5 out of 10 errors were improved after the update, but 5 out of 90 previous correct cases were newly added to the errors?
Overall, 90 out of 100 are correct, so 90% of the performance is the same, but users feel the change in 10 cases. 5 errors improved, but 5 working cases do not anymore. From the user's point of view, of course they may feel delighted that some things started working. However, there is also a risk that they may not discover the improvement because they already adapted not to use your product in the cases it did not work before.
The more important cases are when the model update breaks what used to work. If something that always worked out doesn't suddenly work out, the users will feel uncomfortable immediately.
The bottom line is that If the behavior of your product has high variance due to a ML model, the reliability and usability of your product can be at risk.
To mitigate this risk, the product development team should use the new version after monitoring the performance increase/decrease and volatility with the evaluation set they built (and have a good system to keep track of this) rather than updating as soon as the new ChatGPT version comes out. It's like doing integration testing before updating the library you depend on.
5. Is speed (latency) important to your product?
This is the easiest part to understand, but easy to overlook. ChatGPT is a huge model, so even if you parallelize GPUs, it still takes time to generate text, yet. In fact, if you use the GUI, you can see that it takes time to generate text. (Feels slower in Korean because Unicode is used).
Does speed (latency) matter to your users? Or can they wait a little bit? Or they don’t experience the wait? It really depends. For example, if the product is a customer center chatbot that responds by email, it's probably okay because the user doesn't experience the wait. When you get the email, it is instant. However, if it is a chatbot, basically it is the same as waiting for a person to finish typing.
What if a game NPC was implemented with ChatGPT? Of course, it would be amazing to have a realistic conversation with the game NPC, but if it takes 10 seconds per turn, it would be super annoying.
6. What is the legal implications?
The last but not the least point is the legal responsibility. I haven't read all the terms and conditions of OpenAI, but Professor Emily Bender points out something very important in the tweet below:
Was just perusing @OpenAI 's terms of service and was a little surprised to find this. Are they really saying that the user is responsible for ensuring that #ChatGPT's output doesn't break any laws?
— @emilymbender@dair-community.social on Mastodon (@emilymbender) February 1, 2023
Source: https://t.co/VPWd2InRb5
>> pic.twitter.com/NgYecfAZc9
Input/Output (combined content) entering and exiting through the API can sometimes be used by OpenAI to improve and maintain services.
The legal responsibility arising from the content lies with you.
Let’s think about Input first. If we integrate the ChatGPT API, then you are providing your data to a third party, OpenAI. I think this should be clearly stated and agreed through the terms and conditions. And we should be more careful not to let sensitive personal information go through the API.
The second point is a greater risk. As discussed in the previous post, ChatGPT has clear limitations on factuality (a.k.a. bullshitting). But what if a ChatGPT-based product harms the user through some false information? Or if the user was given direct advice on crime planning? It seems that the legal responsibility for this lies not with OpenAI, but with the product development team using the APIs.
Before productionizing ChatGPT, it would be essential to review the product's terms and conditions and assess the legal risks first.
In this post, I talked about the things to consider before making a product with ML APIs, such as ChatGPT. There are more than you would imagine. Anyone can simply link the API, but actually making it a useful product is quite difficult. As with all tech products, I think only the teams with excellent engineers and product managers can tame the monster to make (good) impact.
OpenAI CEO Sam Altman says he expects 1B$ revenue in 2024 through ChatGPT. However, in order to achieve this, many companies, including startups, will need to know how to use the API effectively. But I think OpenAI just released a monster, but it didn't show up with a way to tame it. While there is an argument that this enables anyone to easily use the AI magic, I do not think every development team can effectively “productionize” large language models like ChatGPT to their products (hope my prediction is wrong!).
It makes sense that OpenAI has received a strategic investment from Microsoft, a big tech company, with an army of excellent, elite engineers and product managers. They start taming the monster by throwing not thousands, millions of ropes. A lot of teams will fail, but some teams will be very very successful. Microsoft Teams has already released features linked to OpenAI's model, and all eyes are on Bing.
Will ChatGPT-linked products pour out in the future? How many of those will be chosen by users?
*disclaimer: The ideas in my blog are my own, but do not represent my employer Google. I only use public information to write.