Week 14 - 숫자만 잘 세도 NLP 모델이 된다? N-gram language model


지난 주 글에서 Language Model (LM)이 무엇인지에 대해서 배웠습니다. 어떠한 문장이 주어졌을 때 얼마나 그럴 듯 하냐를 확률(probability)로 나타내는 것이 LM의 핵심 개념입니다. 그렇다면 생각만 해도 복잡한 확률을 어떻게 계산할까요? 그건 바로 여태까지 읽은 문장, 즉 데이터에 있는 단어들을 하나하나 다 세보는 것입니다!
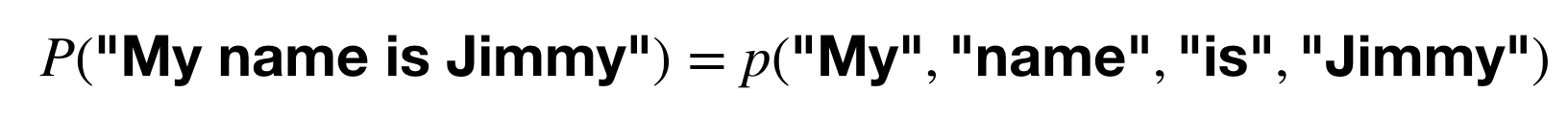
간단하게 생각해봅시다. 우리의 데이터를 우리가 다른 사람에게 말한 모든 문장이 포함되어있는 엄청나게 거대한 데이터라고 생각합시다. 몇 억 아니, 몇 조, 아니 셀 수 없는 문장이 데이터 안에 들어가있겠죠. 그렇다면 어떤 문장이 이 데이터에 몇 번이나 나타나는지 세어보면 되는거 아닌가요? 맞습니다! "수고하셨습니다!", "네", "아니요", "사랑합니다" 같이 정말 자주 사용하는 문장은 꽤나 자주 나타날 것이고,
확률은 총 빈도수 / 전체 데이터 수이기 때문에 이론적으로는 틀린 방법은 아닙니다.
하지만 이 방법은 아주 치명적인 문제가 있습니다. 그건 바로 세상에는 무수히 많은 단어 조합이 있다는 점이죠. 세상에 모든 문장을 데이터로 모아도, 언제나 새로운 단어 조합의 문장이 있을 수 밖에 없습니다.

만약 기존 데이터에서의 빈도 수를 세는 식으로 계산하면 새로운 문장의 확률은 무조건 0으로 계산될 것 입니다. 이런 문제를 머신 러닝에서는 data sparsity라고 합니다. 학습 데이터가 모든 경우의 수를 커버하지 못하기 때문에 생기는 문제입니다. input이 복잡한 문제일수록 이러한 문제가 생기겠죠?

단순하게 생각하자 uni-gram, bi-gram!
그렇다면 한 번에 모든 단어를 생각하면 너무 복잡하니깐 조금 더 단순하게 생각해봅시다. 일단 문장에 있는 단어를 개별적으로 생각해본다면?
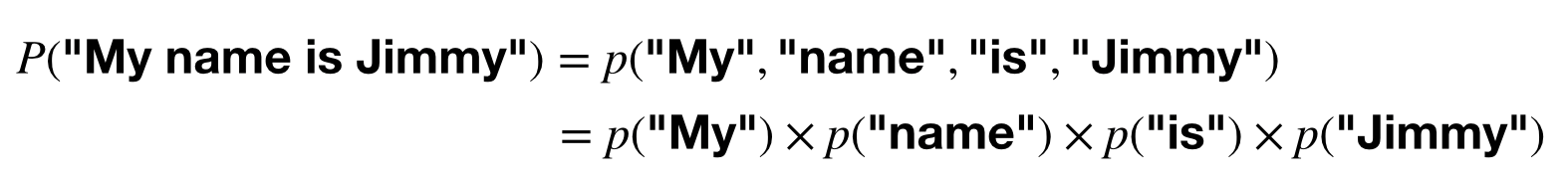
1. 각 단어가 나타날 확률은 단어 별 빈도수를 계산해서 전체 단어 수로 나누어줍니다.
2. 문장 전체의 확률은 간단하게 곱해줍니다.
전에 다룬 bag-of-word + tf-idf 모델이 기억 나시는 분이 있으신가요? 이걸 unigram (1-gram) 모델이라고 합니다. 계산이 단순하다는 장점이 있지만, 치명적인 단점이 있습니다. 바로 단어의 순서를 전혀 생각하지 않는다는 것! bag-of-words (BoW) vector 모델과 같은 단점입니다. 문장이라는 게 단어 간 순서와 상관관계가 중요한 것 아니겠습니까?
"The show killed Jimmy." (쇼가 지미를 죽였어.)
"Jimmy killed the show." (지미가 쇼를 죽였어)
이렇게 순서에 따라 엄청나게 의미가 달라질 수 있습니다. 그렇기에 문장의 확률 역시 상당히 다르겠지요. 그렇기 때문에 unigram model은 좋은 모델이라고 할 수 없겠죠.
그럼 한 번에 두 개씩 생각해보는 건 어떨까요? 그렇다면 Conditional Probability (조건부 확률)을 알아야 합니다.

*Conditional probability P(w2|w1)는 w1이 주어졌을 때 w2가 올 확률을 말합니다.
위 예시의 P("name" | "My")는 "My" 다음에 "name"이 확률이죠. 잘 생각해보면 "My name"이라는 단어들은 같이 쓰이는 경우가 많으니깐 이 확률은 꽤 높은 편이겠죠? 이런 식으로 붙어 있는 두 단어의 확률을 계산하는 방법을 bigram (2-gram) 모델이라고 합니다. "My" 다음에는 ["name", "house", "school"] 같은 단어들이 ["is", "her", "played"] 같은 단어들보다 훨씬 더 자주 쓰이기 때문에 조건부 확률도 훨씬 높을 것입니다.
여기서 또 재밌는 건 <start>와 <end> 토큰인데, 어떤 단어가 문장의 시작 또는 끝에 나올 확률을 계산하기 위해 bigram 계산할 때 포함하여 계산합니다. 예를 들어, P(<end> | "my")는 P(<end> | "him") 보다 훨씬 작겠죠. "My"로 끝나는 문장은 거의 없을 테니깐요.
잘 세기만 해도 강한 n-gram LM
이처럼 한 번에 n개의 연속된 단어를 묶어 생각하는 것을 n-gram LM이라고 합니다. n=3 이면 P(w3 | w2, w1)을 계산하는 식으로 각 단어들 간의 연관성을 고려하여 한 문장의 확률을 계산할 수 있습니다. n이 늘어날수록 계산해야 하는 항목도 늘어나기 때문에 보통 1-gram, 2-gram, 3-gram을 섞어서 통계 모델을 만듭니다. 이렇게 단순한 방법도 데이터가 많으면 생각보다 성능이 매우 좋은 모델이 탄생합니다. 그게 바로 데이터의 힘이죠.
예를 들어, 구글이 쌓은 방대한 책 데이터베이스를 봅시다. 구글은 이 데이터를 가지고 Google Books Ngram Viewer라는 아주 재밌는 툴을 공개했습니다. 어떤 n-gram을 적어 넣으면, 각 시대마다 얼마나 큰 확률로 데이터에 나타나는지 보여줍니다.
"My name"과 "My her"를 비교해보면, "My her"는 문법적으로 틀렸기 때문에 확률이 거의 0으로 수렴합니다.
이처럼 "artificial intelligence"는 1980년~90년도에 꽤나 많이 언급되다가 현재는 점차 줄어들었습니다. "machine learning"은 1980년도에 등장해서 지금은 AI보다 더 많은 확률로 데이터에 나타납니다. 놀랍게도 "computer science"보다도 높은 확률이네요. 현재 AI/ML에 얼마나 큰 관심이 몰리고 있는지 나타내는 반증인듯 합니다.
"Google it"이라는 bigram은 Larry와 Sergey가 창업한 2000년도 이후로 폭발적으로 증가합니다. 없다 새로운 동사가 되었기 때문이겠죠.
나름 사회/역사적인 분석도 할 수 있습니다. 영국식 영어인 "favourite"와 미국식 영어인 "favorite"를 살펴보면 1900년대 초반 전후로 확률이 크게 차이가 납니다.
이렇게 비교적 간단(?)하게 n-gram LM에 대해서 이야기해보았습니다. 많은 데이터가 있다면 n-gram 모델도 꽤나 좋은 퍼포먼스를 낼 수 있다고 알려져 있습니다. n-gram LM을 만들 때에는 다른 정보 필요 없이 문장 자체만 있으면 되기 때문에 글만 있다면 무제한적으로 큰 데이터를 갈아 넣을 수 있습니다. 양이 많을수록 통계가 그만큼 더 정확해지겠지요.
이제는 LM의 개념은 이해되시겠지만, 이게 아직 왜 중요한지, 실제로 어떤 것에 쓰이는지 잘 감이 안 오시는 분들도 계실 것 같습니다. 그래서 다음 주에는 LM의 중요한 응용 사례인 자동음성인식 (automatic speech recognition; ASR)에 대해 글을 써볼까 합니다. ASR은 우리가 Google Assistant나 Siri에 말을 할 때, 음성을 텍스트로 바꿔주는 기술인데요. 요즘은 워낙 상용화가 많이 되어 다들 한 번쯤 써보셨을 만큼 그 원리를 공부해보시는 건 어떨까요?
+심화
만약 이미 학습된 n-gram 모델에 새로운 단어 (out-of-vocabulary; OOV)가 들어간 문장을 넣으면 어떻게 될까요? N-gram 모델은 통계 기반이기 때문에 처음 본 단어는 무조건 나타날 확률을 0으로 계산하겠지요. 근데 OOV 단어 하나 때문에 전체 문장이 0이 되는 건 뭔가 너무 멍청한 거 같지 않나요? 이러한 경우가 은근히 많기 때문에 n-gram LM을 연구하는 분들이 smoothing이라는 테크닉으로 이를 극복합니다. 혹시 이에 대해 더 읽고 싶으시다면 아래 리소스를 참고하세요!

Reference
- Speech and Language Processing, Chapter 3: N-gram Language Models, Daniel Jurafsky & James H. Martin.



