Week 33 - 문제가 될 것을 미리 알았어야 했다 <AI 챗봇과 윤리 2편>


Why We Should Have Seen That Coming, 학회에 발표된 논문치고는 굉장히 특이한 제목입니다. 직역을 하자면, "왜 우리는 그것이 올 것을 이미 봤어야 했다," 즉 우리는 문제가 될 것을 미리 알았어야 했다는 것이죠. 이 논문은 바로 2016년에 공개되었다 24시간 만에 내린 마이크로소프트의 테이(Tay) 이슈에 대해 이야기합니다.
당시에도 많은 논란을 불러일으켰던 테이는 이루다의 데자뷰, 아니 이루다가 테이의 데자뷰로 굉장히 비슷한 논란을 일으켰습니다. 당시 미국의 극우 백인우월론, 인종차별자 등의 유저들이 테이에게 혐오, 성차별 등의 발언을 유도하였고, 테이는 이를 따라하거나 동조하는 메세지를 생성하는 등의 문제를 일으켰고, 마이크로소프트는 일부 사용자들의 악용 사례 때문에 서비스를 중단하였습니다.

이 논문 저자들은 머신러닝 시스템이 인간을 표방한다면 좀 더 큰 윤리적 책임을 가져야 한다고 말합니다. 테이의 개발자들은 프로필에 인간 여성 얼굴을 한 사진을 올리고 "인간처럼" 대화할 수 있는 봇이라고 했기 때문에, 이건 "진짜 사람이 아니라 그저 로봇이야"라는 주장은 큰 힘을 지니지 않는다고 이야기합니다 (필자: 근데 왜 이러한 AI봇들은 항상 여성일까요...?). 개발자들의 목적은 사람들이 테이를 "인간으로" 느끼기를 원했기 때문이죠. 그렇기 때문에 제대로 된 테스팅 후 이러한 문제를 방지를 하지 않고 대중에게 공개한 것은 비윤리적일 뿐더러 해야할 일을 성실히 하지 못한 것이라고 비판하고 있습니다.
당시에 마이크로소프트에서도 이건 단지 기술 발전을 위한 실험이었을 뿐이라고 했지만, 좋은 과학이라면 제대로 컨트롤된 환경에서 자원봉사자로 이루어진 실험 대상들을 통해 이루어졌어야 한다고 주장합니다. 테이와 일부 악용 유저들이 한 대화가 소셜 미디어에 공개되면서 그들의 실험에 비자발적으로 많은 사람들이 "참여"하게 되었고, 여성/소수인종 등의 유저들은 심각한 언어폭력에 노출되었습니다. 이는 기술 개발자로 책임있는 행동이 아니라고 강조합니다. 특히 AI와 같이 사회에 큰 파장을 일으키는 기술이라면요. 새로 나온 폭탄 기술을 실험한다고 사람들이 다닌 거리에서 막 터뜨릴 수는 없는거 아니겠습니까.

이번 <위클리 NLP>에서는 테이 사태 이후에 챗봇 개발/연구자들이 또 다시 이런 사태가 반복되지 않도록 어떤 노력을 해왔는지에 대해서 다루어보려고 합니다.
특히 두 가지 측면 - (1) 언어 폭력 대응, (2) 팩트 체크 - 에 대해서 공부해보겠습니다.

언어 폭력에 대응하는 챗봇
언어 폭력(abusive/offensive language)는 굉장히 까다로운 문제입니다. 단순히 키워드로 잡아낼 수 있는 것이 아닙니다. 채팅 기능이 있는 온라인 게임을 해보신 분들은 인간들이 어떻게 이러한 시스템은 간단히 회피할 수 있는지 잘 아실 것 입니다. (많이) 순화된 예시로 한번 봅시다.
"야 이 나쁜 친구야" =>"야 이 낫픈 친!구!야"
그렇기 때문에 데이터 기반의 솔루션이 필요합니다. 하지만 항상 그렇듯이 데이터를 쌓는 것이 문제입니다.
저는 2017년에 첫 논문으로 언어 폭력, 특히 성차별적 발언과 인종차별적 발언을 딥러닝 모델으로 거르는 연구를 발표했습니다. 기술적으로는 딱히 특별한 연구는 아니었습니다. 어렸을 때 하던 메이플 스토리의 채팅창과 비슷하게 데이터에 일부러 철자를 틀리게 한 단어들이 많고, 신조어가 많다는 점을 착안하여 문자 레벨(character-level) 피쳐와 단어 레벨(word2vec)을 섞은 Hybrid CNN 네트워크를 써보았죠. 이 때가 언어 폭력 문제를 해결하는 워크샵이 첫번째로 열렸을 때라 이 문제에 딥러닝을 처음으로 적용한 사례였습니다.
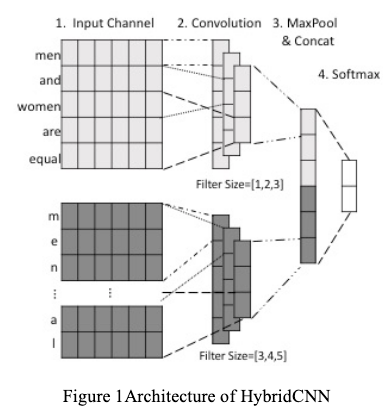
하지만 언어 폭력 데이터는 다른 데이터와 다르게 굉장히 까다롭습니다. 일단 전체 메세지에 비해서 굉장히 적기 때문에 샘플링을 하기가 어렵고, 은어나 신조어가 많이 섞여 있고, 문화적 배경이 없다면 언어 폭력인지 아닌지 판단하기도 어려움이 있습니다. 비꼬는 언어도 많이 사용하고, 긍정적인 단어를 사용하지만 성차별을 조장하는 Ambivalent Sexism 같이 화자의 의도를 파악하기 힘든 경우도 많습니다.
게다가 적은 량의 데이터만 가지고 학습된 시스템은 의도치 않은 경향을 가질 수도 있습니다. 예를 들어, 제가 2018년에 발표한 후속 논문에서는 성차별 언어 데이터를 잘못 학습 시키면 여성 대명사(e.g. she/her)만 나오면 일반적인 문장도 무조건 성차별이라고 예측을 하는 등 편향성을 가질 수 있다는 점을 지적하였습니다.
욕쟁이 인간을 AI의 선생님으로 (Human-in-the-Loop)
이 문제를 해결하기 위해서 페이스북 AI에서는 Human-in-the-loop(이하 HIL) 방법을 사용하였습니다. HIL은 말그대로 사람을 AI 모델의 트레이너, 선생님으로 사용하는 방식인데, 학습된 모델을 사람이 피드백을 주면서 점진적으로 개선시키는 방법을 말합니다 (Active Learning이라고도 불립니다).
특히 요즘 Amazon Mechanical Turk(AMT) 같은 크라우드 워커(CrowdWorker)들을 통한 데이터 레이블링 서비스들의 효율성이 굉장히 좋아지면서 언어 폭력 연구 말고도 다양한 연구와 개발 과정에 HIL이 쓰입니다.
언어 폭력 데이터는 앞서 말했듯이 자연적인 데이터(e.g. 크롤링)에서 쉽게 얻을 수 없다는 점에서 HIL 방식은 매우 매력적입니다.
1. 확보한 데이터로 언어 폭력 분류 모델을 만든다.
2. 사람에게 모델이 분류하지 못하는 문장을 써보도록 한다 (=> 걸리지 말고 욕해봐~)
3. 이렇게 모인 데이터로 모델을 재학습
4. 반복!
여기서 핵심은 2번에서 "걸리지 말고" 입니다. 뻔한 욕설은 이미 기존 모델에게 언어 폭력이라고 분류가 되겠죠. 그렇다면 사람은 안 걸리도록 더 교묘하거나 비간접적인 언어폭력 데이터를 생성해야만 합니다. 일종의 고양이-쥐 게임이죠. 이러한 방식을 적대적 학습(adversarial training)라고도 합니다.
최근에 공개된 따끈따끈한 후속 연구에서는 더 나아가 사람이 챗봇에게 거는 말 뿐만 아니라, 모델이 생성하는 언어에 대해서도 HIL을 통해 적대적 학습을 합니다.
1. 확보한 대화 데이터로 챗봇을 학습시킨다.
2. 사람이 챗봇이 부적절한 말을 하도록 유도 (=>챗봇이 욕하게 만들어봐)
3. 이렇게 모인 데이터로 모델을 재학습
4. 반복!
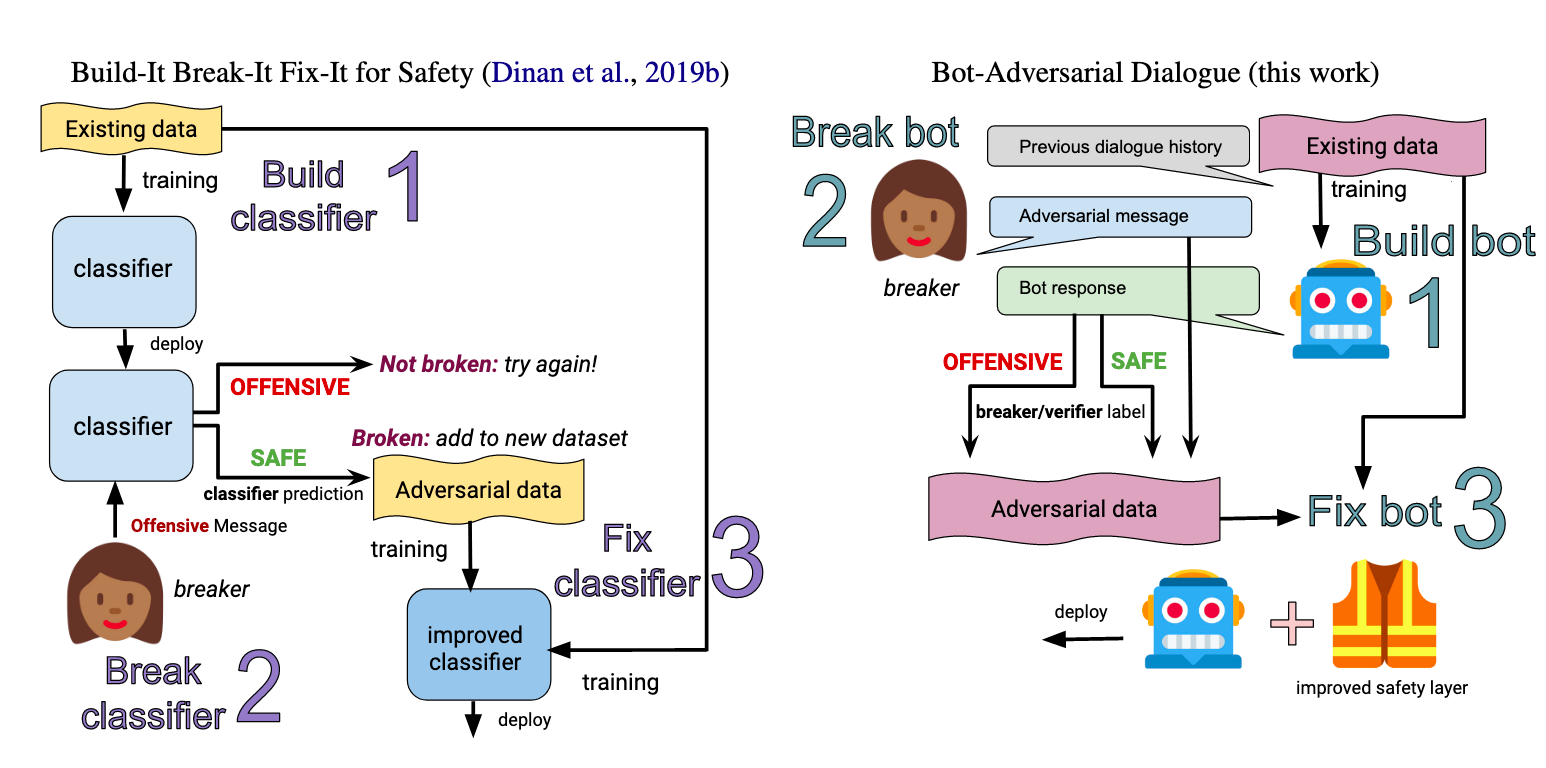
이렇게 모인 데이터는 크게 두 가지 강점이 있습니다.
- 기존 모델을 부술 수 있는 데이터만 모으도록 유도했기 때문에 더욱 다양하고 창의적인(?) 방법으로 폭력적이고 차별적인 언어 데이터를 모을 수 있습니다.
- 대화의 맥락(context)도 함께 모으기 때문에 맥락에 따른 언어 폭력도 대응할 수 있습니다.
앞서 소개한 두번째 논문인 <Recipes for Safety in Open-domain Chatbots>은 좀 더 포괄적으로 어떻게 하면 안전하고 윤리적인 자유주제 챗봇을 만들 수 있는지에 대해 논하고 있으니 관심있으시면 꼭 한번 읽어보시는 것을 추천합니다.
상당히 포괄적이면서도 보수적인 스탠스를 가지고 있다는 것을 느낄 수 있었는데요. 그만큼 테이 사태를 교훈 삼아 이러한 챗봇 개발의 윤리적, 사회적 책임감 (그리고 기업적 리스크)를 중요시 하고 있다는 것을 알 수 있었습니다. 예를 들어, 예민한 주제(종교, 젠더, 정치, 의학 등 이슈)에 대한 대화를 자동으로 원천 봉쇄하도록 디자인해놓았습니다. 특히 의학에 관련된 대화는 잘못된 정보로 인해 누군가의 목숨을 잃을 수 있다는 점을 잊지 않고 시스템 디자인에 고려해놓았다는 것이 대단하다고 느껴졌습니다.
(여담: 구글에서는 시스템 디자인 문서 템플릿에서 Safety & Ethics 부분을 기본으로 포함하고 있습니다. 이러한 default가 직원들이 놓치지 않고 많은 부분을 고려할 수 있게 한다는 점에서 큰 장점이 있는 것 같습니다. 특히 구글이나 페이스북처럼 큰 영향력을 가진 회사들은 이러한 점을 더욱 더 유의해야 한다고 생각합니다.)
팩트체크하는 챗봇: AI니깐 사실에만 기반해서 말하겠지?
사람들 사이에선 AI가 하는 예측이나 결정은 굉장히 공정하고 팩트 기반일 것이라는 환상이 널리 퍼져있는 것 같습니다. 특히 기사에 정치인, 판검사 등을 전부 AI로 바꾸는게 낫겠다는 댓글을 꽤 자주 달리니깐요. 다만, 공정과 팩트 체크는 사람 뿐만 아니라 AI 모델에서도 지식이 잘 설계되지 않으면 이루기 힘든 문제입니다. 특히 공정성에 관련해서는 모델 편향성(Model Bias)에 대한 논의가 많이 이루어져있는데, 좀 더 깊은 내용은 다른 글에서 다루도록 하고 이번 글에서는 챗봇만 생각해보겠습니다.
지난 번에 살펴본 자유 주제형 챗봇의 원리를 다시 한번 곰곰히 생각해보면, 어디에도 팩트 체크는 없습니다. 전부 학습 데이터에 의존하고 있죠. 챗봇에게는 학습 데이터가 진실이자, 이 세상의 전부입니다. 그렇기 때문에 단순히 데이터에만 의존하는 챗봇이 뱉는 말이 거짓을 포함하지 않을 것이라는 보장은 전혀 없습니다.
DB에서 직접 답변을 고르는 모델을 생각해봅시다. 학습 데이터 중에 가장 비슷한 대화 맥락을 찾아서 그 때 사용했던 답변을 재사용합니다.

생성형 대화 모델 역시 확률로 다음 토큰을 생성하는 것이기 때문에 사실을 기반으로 메시지를 생성하는 것은 아닙니다. 그래서 GPT-3 같은 거대한 언어 모델로 생성된 그럴듯한 가짜 뉴스가 판칠 것을 많은 사람들이 걱정하고 있죠.
그렇다면 사실을 기반으로 한 챗봇은 어떻게 만들 수 있을까요? 현재 가장 활발하게 연구되는 방향은 지식 베이스(Knowledge Base)를 이용하는 것 입니다.
지식기반 챗봇?
지식 베이스는 말 그대로 사실로 판명이 된 여러 가지 지식을 쌓아놓은 데이터베이스를 뜻합니다. 형태는 여러가지가 있을 수 있는데, 우리가 잘 아는 네이버 지식in처럼 Q & A 형태로 되어있을 수도 있고, 위키피디아나 나무위키처럼 어떤 주제에 대한 기사로 이루어져 있을 수도 있습니다. 좀 더 정형화된 데이터라면 지식 그래프(Knowledge Graph) 형태가 될 수도 있겠죠.
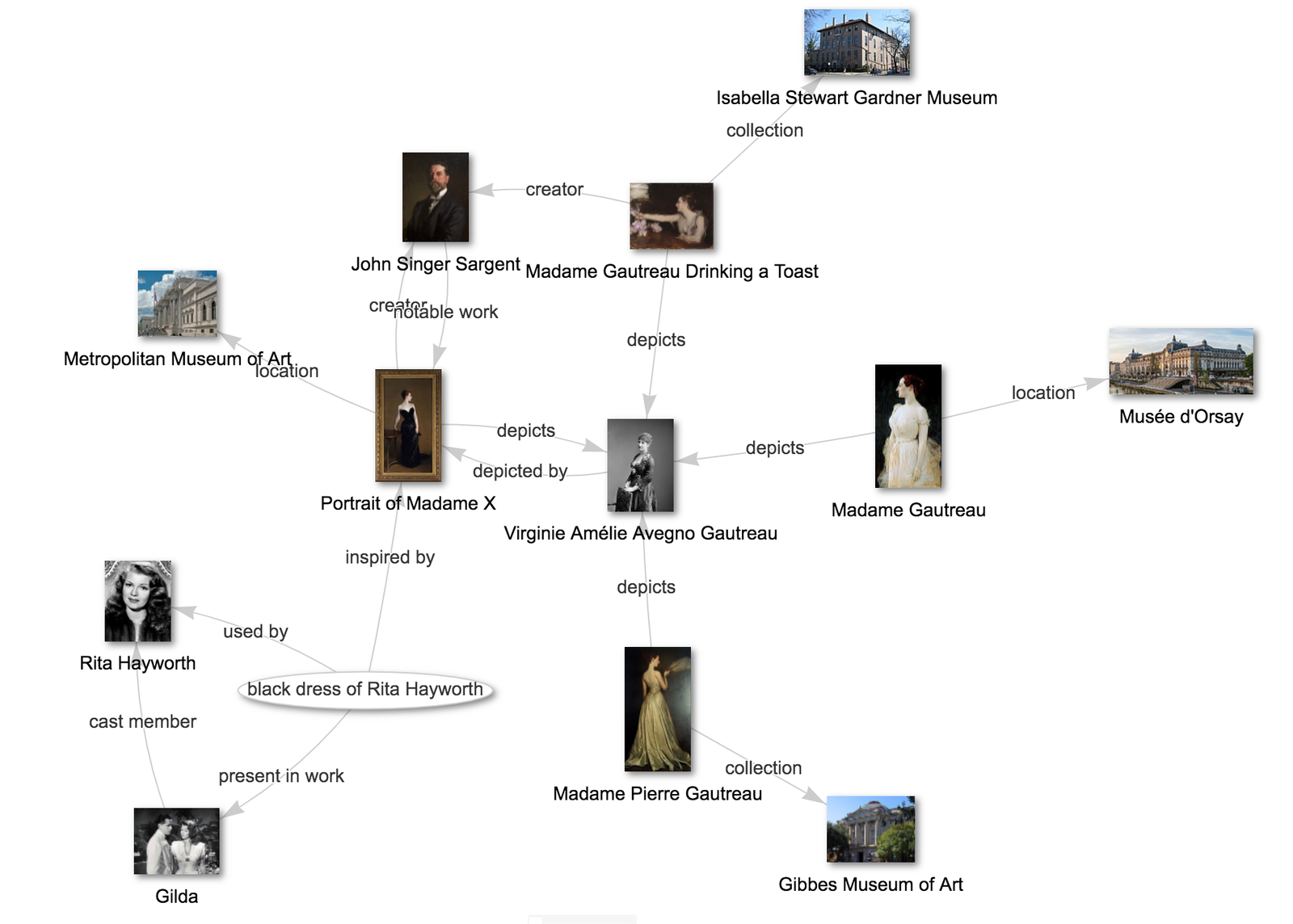
2019년 발표된 페이스북에서 위키피디아를 지식 베이스를 기반으로 하여 대화를 이끌어 나가기 위한 챗봇 학습 데이터와 모델을 공개하였습니다 (위 HIL 연구를 한 같은 팀!). 메모리 네트워크(Memory Network)라는 외부 지식을 잘 끌어다쓰는 모델과 트랜스포머를 결합하였습니다. 사실 이 연구의 목적은 팩트 체크하는 것 뿐만 아니라 좀 더 많은 정보를 통해 흥미로운 대화를 이끌 수 있는 대화 모델을 만드는 것인데 실제로는 어떤지 한번 볼까요?

더 나아가 지식 그래프를 이용하여 연관된 주제를 왔다갔다 하면서 대화를 할 수 있게 학습하는 대화 모델 연구도 최근에 공개되었습니다. 유저가 어떤 주제로 대화를 시작하면 지식 그래프에서 그 주제를 시작점으로 다른 주제에 대한 대화를 자연스럽게 이끄는 것을 목표로 하고 있습니다. 추천 시스템을 대화로 녹여낸 느낌이 나네요.
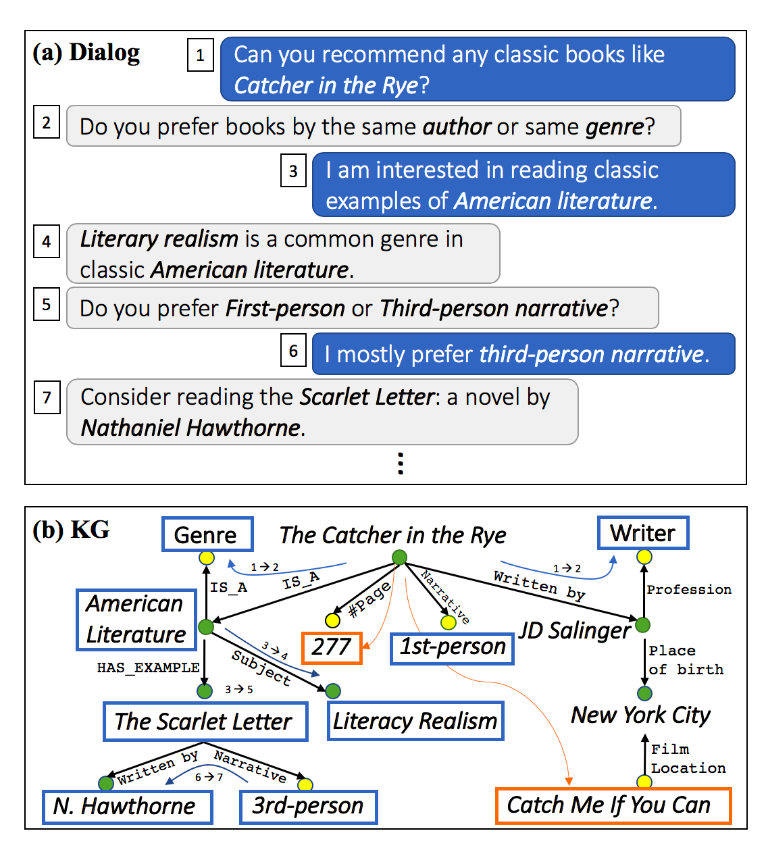
이처럼 자유 주제 챗봇 연구에는 지식 베이스를 기반으로 하여 대화를 생성해, 좀 더 사실에 기반하고 주제에 대한 지식 기반으로 더 흥미로운 대화를 이끄는 방향의 연구들이 지속적으로 시도되고 있습니다.
이번 글에서는 언어 폭력에 적절히 대응할 수 있는 챗봇, 팩트 기반의 챗봇 시스템을 만들기 위한 여러 연구 노력에 대해서 알아보았습니다. 어떤 회사든 연구실이든 개인이든 AI를 이용한 본인의 제품이 단순히 "와, 신기하다!" 같은 반응을 얻는 것에 집중할 것이 아니라, 타인들에게 어떤 영향을 끼칠 것인지에 고민을 많이 해보고, 윤리적 리스크가 있다면 어떻게 줄일 것인지 노력을 해보고 출시되어야 하지 않을까 싶습니다. 아무리 "실험", "베타", "데모"라는 딱지를 붙이고 나와도 이번 이루다 이슈로 보았듯이 예상 외의 파장이 있을 수 있습니다.
이러한 윤리적 문제를 얼마나 대응하는데 노력을 얼마나 해야 적당한 것이냐는 상당히 어려운 문제인 것 같습니다. 확실한 것은 IT/AI 분야에서도 이러한 문제들에 더 민감해져야 한다는 것이겠죠. 그에 대한 동기가 개인적 양심이든, 조직적 문화이든, 경제적 리스크이든. 사실 안정성/윤리 문제는 유저의 생명과 직결되는 의학이나 생명과학 같은 분야의 연구와 제품개발을 하는 사람들에게는 익숙할 것이라고 생각합니다. 이제는 IT/AI 분야 종사자들도 본인들의 영향력을 인지하고, 윤리에 대해 좀 더 책임감 있게 접근해야 하지 않을까 싶습니다.
또한 전세계 여러 연구자들끼리의 협업 역시 중요합니다. 서로의 연구나 제품에 대해서 평가하고 피드백을 주고 받는 문화가 내부 조직에서만 토의했을 시 놓칠 수 있는 문제를 잡을 수 있습니다. 그렇기 때문에 챗봇 연구자들은 어느 NLP 주제보다 더 좋은 커뮤니티를 구축해놓으려고 하는 것 같습니다. ParlAI는 일종의 파이썬 기반 플랫폼으로 챗봇 모델을 공유해 비교한다거나 평가를 위한 템플릿을 쉽게 적용한다거나 페이스북 메신저에 연동을 한다거나 등 여러 기능을 제공하고 있습니다. 그리고 이 플랫폼을 중심으로 여러 프로젝트 및 워크샵이 이루어지고 있으니, 관심 있는 분들은 꼭 살펴보시길 바랍니다. 특히 이번 글에 언급된 많은 연구가 이 플랫폼 기반을 하고 있어 직접 써보고 비교할 수 있다는 점 참고바랍니다. (예: 위키피디아 기반 챗봇 프로젝트)


Reference
- Miler et al., 2017, Why We Should Have Seen That Coming
- 핑퐁 공식 블로그, 2021년 1월 8일: 루다 논란 관련 공식 FAQ
- Park & Fung, 2017, One-step and Two-step Classification for Abusive Language Detection on Twitter, ALW1: 1st Workshop on Abusive Language Online, ACL 2017
- Waseem, 2016, Are You a Racist or Am I Seeing Things?Annotator Influence on Hate Speech Detection on Twitter, EMNLP Workshop on Natural Language Processing and Computational Social Science
- Park et al., 2018, Reducing Gender Bias in Abusive Language Detection, EMNLP 2018
- Dinan et al., 2019, Build it Break it Fix it for Dialogue Safety:Robustness from Adversarial Human Attack,
- Xu et al., 2020, Recipes for Safety in Open-domain Chatbots
- Dinan et al., 2019, Wizard of Wikipedia: Knowledge-Powered Conversational Agents, ICLR 2019
- Moon et al., 2019, OpenDialKG: Explainable Conversational Reasoning withAttention-based Walks over Knowledge Graphs, ACL 2019



