Week 35 - 모델 중심에서 데이터 중심의 AI 개발로


이 글은 DeepLearningAI에서 주최한 앤드류 응 교수의 A Chat with Andrew on MLOps: From Model-centric to Data-centric AI 세미나에 대한 리뷰입니다.
어느 분야이든 주목 받는 역할이 있기 마련입니다. 축구 팀에서는 스트라이커, 밴드에서는 보컬, 회사에서는 CEO, 드라마에서는 주연이 사람들의 시선과 관심을 비교적 많이 받습니다. 하지만 조금만 깊게 알아보면 이 슈퍼스타 뒤에는 더욱 핵심적인 역할, 없으면 전체 시스템이 망가지는 그런 역할 역시 많습니다. 다만 많은 사람들에게 주목을 받지 못할 뿐.
최근 몇 년간 가장 주목을 많이 받은 AI 연구는 항상 모델(Model)이였습니다. 위클리 NLP에서도 CNN Seq2seq Transformer, BERT, GPT 등 다양한 모델의 발전을 다루었습니다. 하지만 연구를 뛰어넘어 실전에서 AI 개발 일을 하다보니 가장 중요한 것은 모델이 아니라 데이터라는 것을 깨닫고 있습니다. (특히 저는 구글 어시스턴트의 데이터 팀에서 일하고 있기 때문에 더 그렇게 느낄지도 모릅니다)
AI/NLP 연구를 살펴 보다 보면 데이터의 중요성을 간과하기 쉽습니다. 각기 다른 모델의 성능을 똑바로 비교하기 위해 벤치마크 데이터 셋을 사용하고 있기 때문이죠. MNIST, CIFAR, SST, SQuAD 등 이 약자들이 눈에 익숙하시다면 무슨 말을 하는지 아실 겁니다. 이러한 한계를 극복하기 위해 ACL에서는 Best Resource Paper라는 이름으로 훌륭한 데이터 관련 연구에 상을 주고 있지만, 새로운 데이터에 대한 연구는 확실히 주목도가 떨어집니다.
실제 일을 해보면 데이터를 어떻게 전처리(preprocessing)하는지, 어떻게 데이터를 모았는지, 크기가 어떤지, 얼마나 퀄리티가 좋은지, 어떻게 학습/평가 셋을 나누었는지 등이 AI 시스템 개발에 큰 영향을 끼친다는 것을 알 수 있습니다. 그럼에도 불구하고 많은 논문과 리포트는 이러한 부분을 크게 서술하지 않거나 최악의 경우 빠트리는 경우도 많습니다. 결국 데이터 관련 지식은 모델링과는 다르게 "해본 자"만 아는 노하우가 되고 있지 않나 싶습니다.
이러한 생각이 스멀스멀 제 머리 속에 쌓일 때 때마침 코세라(Coursera)의 머신러닝 강의로도 유명한 앤드류 응(Andrew Ng) 교수님이 2021년 3월 25일, 머신러닝 시스템 개발: 모델 중심에서 데이터 중심으로 을 진행하였습니다.
이번주는 이 세미나에 대한 리뷰입니다. 세미나의 핵심 내용을 요약하고 제 경험과 생각에 비추어 글을 써보았습니다. 제가 모든 부분을 세세하게 다루지는 않기 때문에 녹화본도 함께 보시기를 추천합니다.



코드만 주구장창 고치지 말고 데이터를 보자

*세미나와 마찬가지로 머신러닝(ML)과 AI는 동의어로 쓰겠습니다.
응 교수님은 당연한 것 같으면서도 아닌 것 같기도 한 정의로 시작합니다:
AI 시스템은 코드와 데이터로 이루어져있다.
그럼에도 불구하고 자신의 경험상 많은 팀들이 더 잘하기 위해서 Code를 고치는데에만 신경을 쓴다고 합니다. 여기서 Model/Algorithm은 모델 구조, 하이퍼파라미터 튜닝(hyperparameter tuning), 학습 방법(ex. optimizer, learning rate, early stopping) 등을 말합니다.
하지만 "실질적으로 AI 시스템의 성능을 높이는 것은 코드의 대한 개선이 아니라 데이터에 대한 개선이다"라고 합니다.
이를 뒷받침하게 위해 여러 케이스 스터디를 보여줍니다. 컴퓨터 비전을 이용한 철강 합판이나 태양광 패널 등의 결함을 찾는 문제에서 모델을 고치는 작업을 했을 때와 데이터를 고치는 작업을 했을 때 개선된 시스템 성능을 보여줍니다.
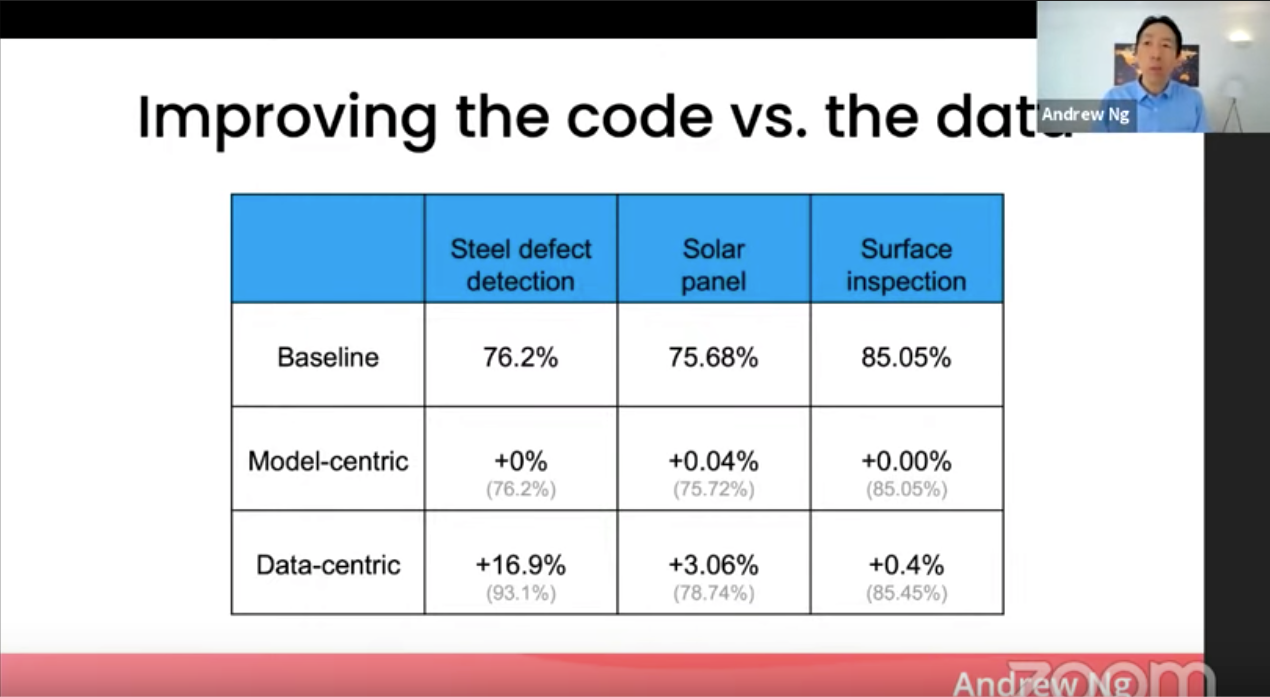
(세미나의 주제와 부합하듯이) 모델을 고치는 작업했을 때는 거의 증가가 없지만, 데이터를 고쳤을 때는 증가폭이 훨씬 큽니다. 물론 문제마다 다르겠지만, 응 교수님은 경험상 이러한 경우가 상당히 많다고 이야기합니다. 그래서 "우리 코드는 전혀 건들지 말고, 데이터를 개선하는데에만 신경쓰자!"라고 해보는 경우가 많았고, 이럴 때 더 좋은 결과가 나온 경우가 많다고 합니다.
케이스 스터디: 음성인식 시스템 (ASR)
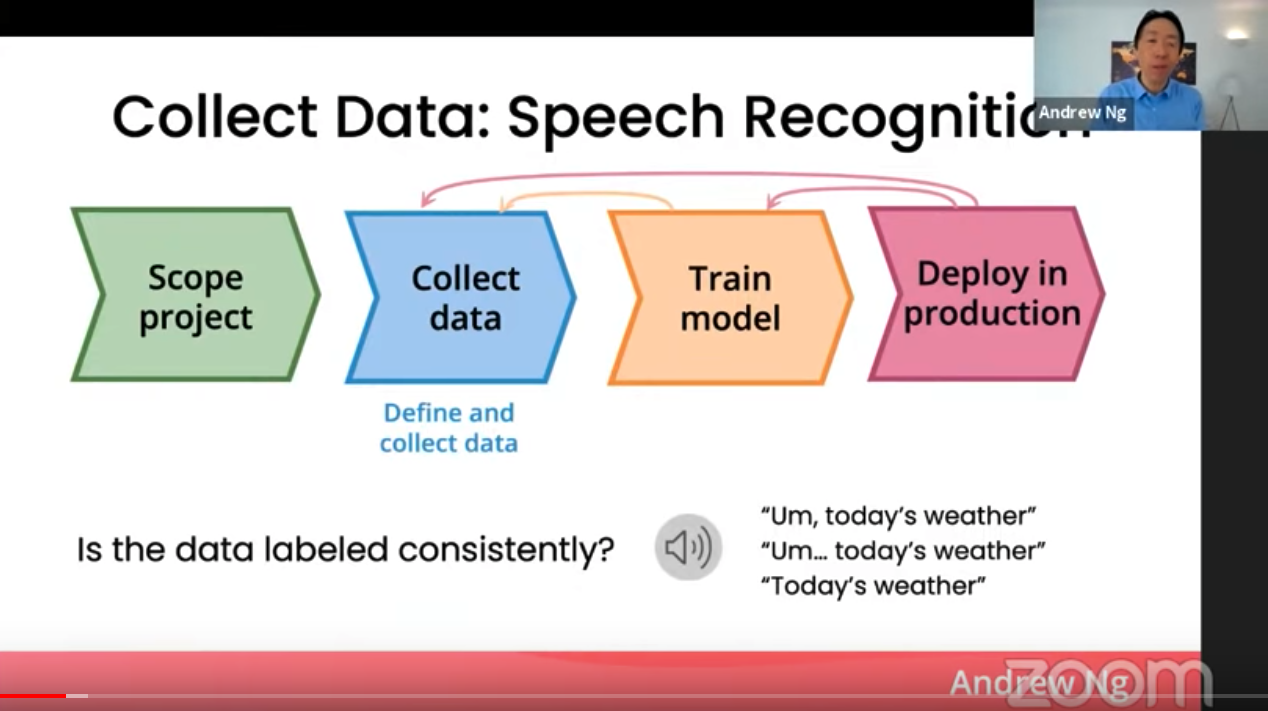
ASR 시스템을 개발하려면 먼저 누군가의 목소리가 들어간 음성 데이터 그리고 말한 텍스트 데이터 쌍을 모아야 합니다. 그런데 만약 음성에 "음(Um).."이라는 부분이 있으면 어떻게 해야할까요? (들어보기)
(이를 언어학적으로는 Filler라고 하는데, 비슷한 예로 "저기..", "어..", "그.." 등이 있습니다. 우리 인간들은 이러한 단어들을 자동으로 거르고 듣는 능력이 있지만 AI 모델에게는 상당히 까다로운 언어학적 현상입니다)
이 음성은
Um, today's weather
Um... today's weather
Today's weather
이 세 가지 정도로 라벨링할 수 있을텐데 어떤 것이 옳을까요?
정답은: "셋 다 괜찮지만 모든 데이터가 일관적(consistent)이여야 한다"입니다.
만일 데이터에 "음(Um).."이 들어가 있다면 AI 모델은 그 음성 부분을 텍스트 Um으로 매핑하게 학습할 것이고, 만일 없다면 그냥 무시하도록 학습할 것 입니다. 그런데 만약에 어떤 데이터에서는 "음(Um).."이 있고, 어떤 데이터에는 없다면 어떻게 될까요? 모델은 데이터에 의존하기 때문에 혼란스러워할거고, 시스템의 예측 결과가 불안정해질 위험에 노출됩니다.
이러한 케이스를 보면 몇 가지 질문이 생깁니다.
Q: 아니, 이런 작고 사소한 것 때문에 모델이 불안정하다고? 데이터만 많으면 되는거 아니야?
네, 안타깝게도 AI는 흑마법이 아니라 데이터에 모든 것이 달렸습니다. 이러한 한계를 인정하고 데이터 퀄리티 높이는 것에 집중해야 합니다. 이러한 부분을 미리 방지하지 않으면 최악의 경우 데이터를 처음부터 다시 수집해야 되는 지경까지 갑니다.
Q: 데이터 수집할 때 조심하면 되는 것 아닌가? 라벨링이 그렇게 어려워?
맞습니다. 처음에 데이터 수집할 때 이러한 문제를 미리 예측하는 것이 핵심입니다. 만일 크라우드워커(Crowdworker)들을 통해 데이터를 수집하는 것이라면 정확한 가이드라인을 주는 것이 중요합니다. 하지만 저는 이게 단순한 문제가 아니라고 생각합니다.
1) 이러한 문제를 미리 예측하기 힘들다
위의 "음..."의 경우처럼 무척 작고 사소한 경우가 많습니다. 그렇게 때문에 데이터 수집 과정을 디자인하는 사람들이 직접 자신들의 라벨링 테스크를 여러 번 해보고 문제를 미리 찾아내는 것이 굉장히 중요합니다. 어찌보면 당연한거 같긴 한데 바쁘다 보면 데이터 라벨링 테스크를 직접 해볼 시간을 내기가 어려울 수도 있습니다. 그렇기 때문에 모든 데이터를 한꺼번에 내보내기 보단 일부분부터 테스트해보는 것이 좋습니다.
2) 크라우드워커(CrowdWorker)들의 품질 관리가 어렵다.
크라우드워커들은 적은 시간에 최대한 많은 테스크를 해야 하고, 테스크당 단가가 낮은 경우가 많아 100% 완벽한 데이터를 만들 것을 기대하면 안됩니다.
응 교수님 역시 (1), (2) 부분을 이야기하며 아래 같은 해결책을 제시합니다.

a. 두 명의 독립적인 워커(labeler)에게 데이터의 일부분을 라벨링하도록 준다
b. 두 명의 라벨이 얼마나 일치하는지 계산한다.
c. 일치하지 않는 라벨에 대해 가이드라인을 수정하고, 일관적인 라벨링을 얻을 수 있을 때까지 반복한다.
*이러한 크라워드워커를 이용한 데이터 수집 과정은 최근 AI 시스템 개발에 핵심 중에 핵심이 되고 있습니다. 한국 뿐만 아니라 전세계적으로 많은 스타트업 역시 뛰어들고 있는 것이 눈에 띄기도 합니다. 이쪽 부분에 대한 연구도 많이 진행되고 있는데, 관심이 있으시다면 저도 최근에 참석했던 Conference on Human Computation and Crowdsourcing(HCOMP2020) 을 보셔도 좋을 것 같습니다.
데이터의 양과 질의 상관관계
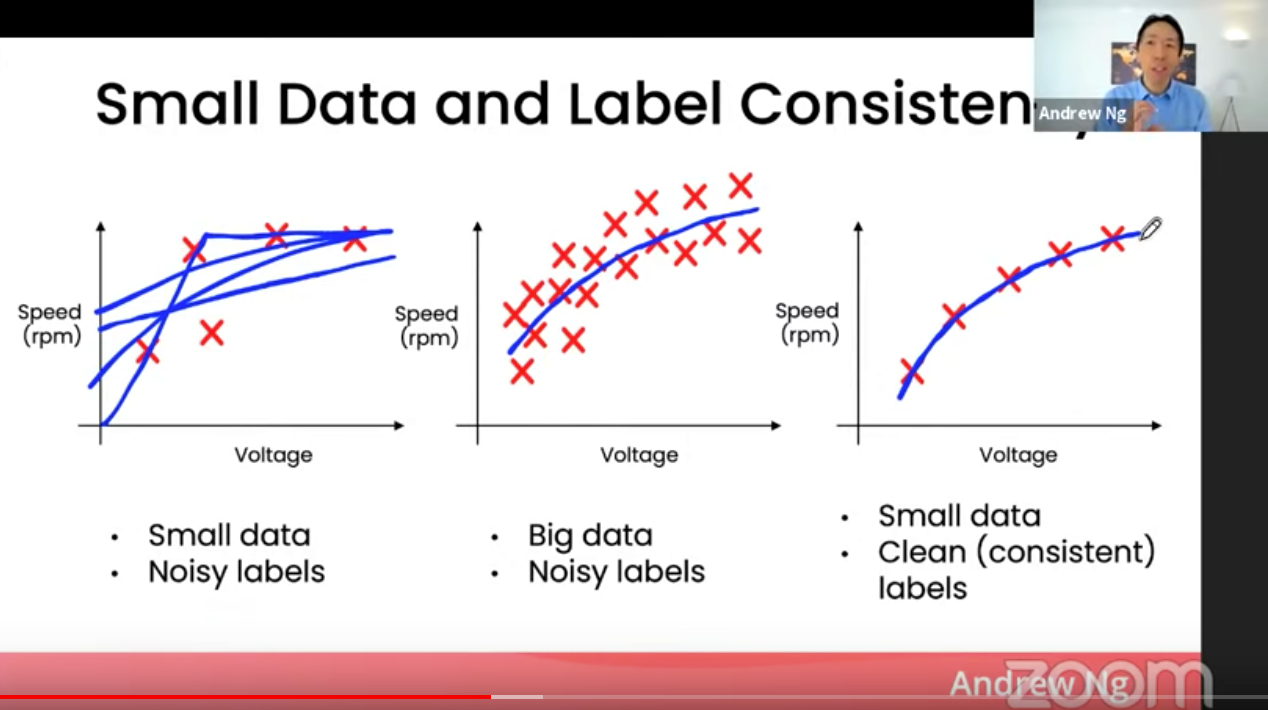
이 차트를 보면 단숨에 데이터의 양과 질의 상관 관계에 대해 어떤 이야기를 하고 싶은지 알 수 있습니다. 여기서 Noisy하다는 것은 원래 데이터에 소음이 있고 질이 낮다는 표현입니다. 반대로 라벨이 일관성이 있다(label consistency)는 것은 질이 높다는 것이죠.
1) 데이터가 많으면 Noisy한 데이터가 있어도, 모델이 올바른 결정 커브(decision curve)를 찾을 수 있다.
2) 반대로 데이터가 적으면, 라벨의 일관성과 질이 모델 퍼포먼스에 큰 영향을 끼친다. (=Garbage in, Garbage out)
만약 이미 있는 데이터에 품질 문제가 있어 모델 퍼포먼스에 부정적인 영향을 끼치고 있다고 판단이 되었다면, 어떤 전략을 사용해야 하는 것일까요?
앤드류 응 교수님은 이론적으로 동일한 두 가지 전략을 제시합니다.
- 데이터의 일부분을 고쳐 소음을 제거한다
- 새로운 질 높은 데이터를 수집하여 학습 데이터를 늘린다.
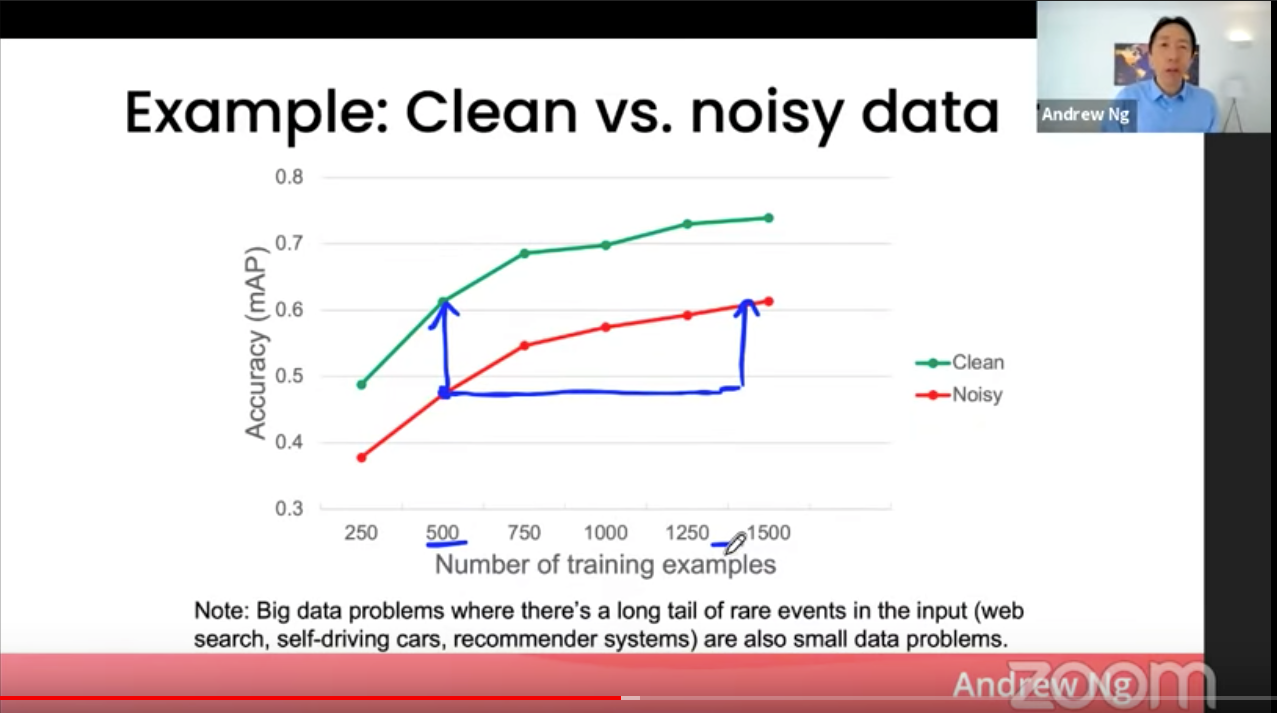
다만, 위 그래프를 보면 100% 깨끗한 데이터를 가지고 학습한 모델과 소음이 섞여있는 데이터를 가지고 학습한 모델을 비교하면 무려 2배 이상의 데이터가 있어야 동일한 성능을 낼 수 있다는 것을 알 수 있습니다. 물론 데이터마다, 문제마다, 모델마다 경우에 따라 매우 다르겠지만요.
데이터를 중심으로 AI 시스템을 개선하는 전략이란?
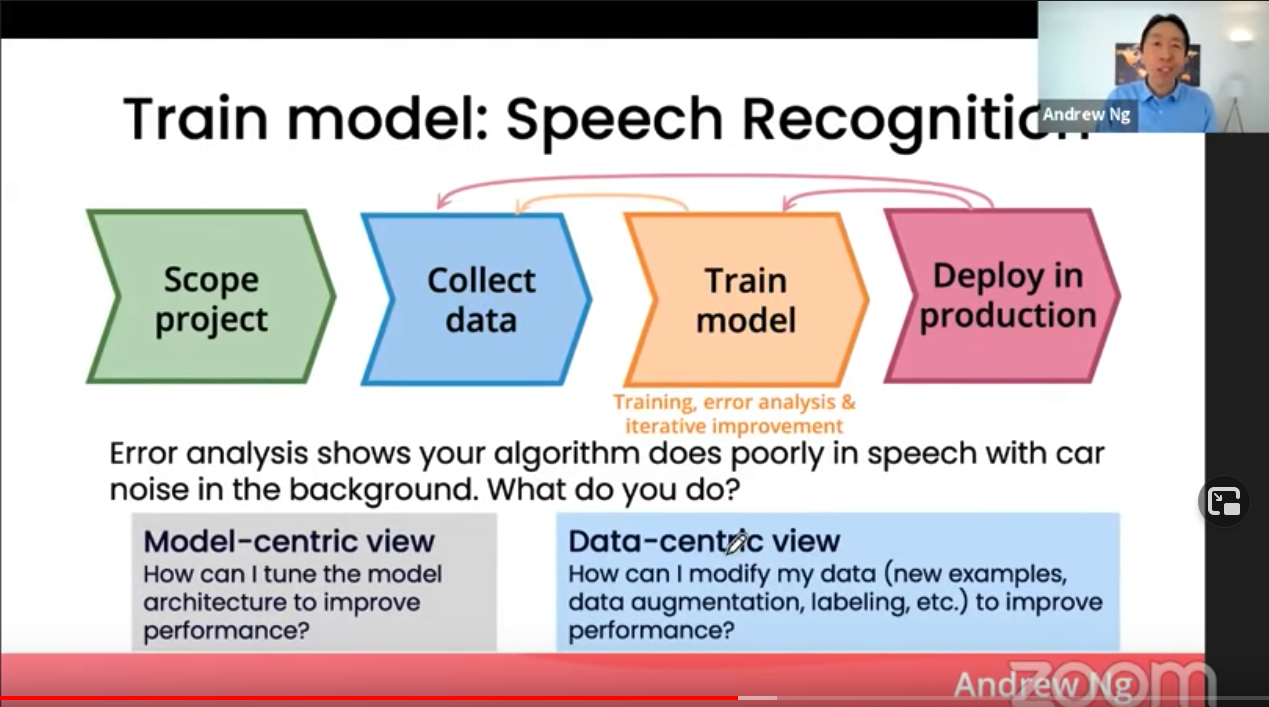
<ASR 시스템 개발 사이클>
- 확보한 데이터로 첫 AI 시스템을 학습시킨다.
- 실전에 투입한다.
- 에러 분석을 통해 시스템이 잘 못하는 부분을 발견한다.
- 개선 시킨다. 어떻게?
만약에 개발한 ASR 시스템이 차 안에서의 음성을 잘 인식하지 못한다고 발견했다고 칩시다. 4번 개선 단계에 어떻게 해야할까요?
- 모델 중심 관점: 모델 구조/학습 방법을 어떻게 바꾸어야 차 안 같이 다른 도메인(out-of-domain)에서 좀 더 일반화를 잘 할 수 있을까?
- 데이터 중심 관점: 데이터를 추가로 수집해야 할까? 이미 있는 데이터를 합성하여(data augmentation) 다른 도메인 데이터에서 퍼포먼스를 올릴 수 있을까? 라벨링 방법을 바꾸어야 할까?
앤드류 응 교수님은 데이터 중심적인 관점을 가지고 개선 방법을 찾는 것이 효과적이라고 주장합니다. 차 안에서 녹음된 데이터를 더 수집한거나 이미 있는 데이터에 차 안 백그라운드 소리를 합성하는 등의 해결 방안부터 살펴보아야 한다고 합니다.
케이스 스터디: 아기 울음소리 감지 시스템
*이 부분은 세미나에 포함된 내용이 아니라 저의 경험을 비춘 내용입니다.
제가 2019년에 일했던 스타트업에서 아기 울음소리 감지 시스템을 개발했던 경험을 소개합니다. 이 제품은 육아용 스마티 스피커로 아기 방에 놓고 쓰는 제품입니다. 부모들을 인터뷰 하다 보니 아기가 울면 알려주는 기능이 굉장히 중요하다는 것을 깨닫고 바로 머신러닝 기반 감지 시스템 개발에 들어갔습니다. (참고로 미국 부모들은 어렸을 때부터 다른 방에서 재우는 경우가 많다고 합니다)
이 때 데이터 수집/가공하고 가이드라인을 만들어 바로 라벨링 작업에 들어갔습니다. 처음 디자인한 것은 굉장히 간단한 라벨링 테스크였죠.

이렇게 수집한 데이터로 첫 모델을 학습시키고 다른 데이터에 적용시켜 검증할 겸 들어보았습니다.
(아직 제가 애가 없는데.. 이 때 매일 아기 울음소리 듣는게 제 하루 일과였습니다...)
이 때 발견한 문제가 크게 두 가지였습니다.
- 애기가 우는게 아니라 좀만 칭얼되도 우는 것이라고 분류.
- 애기가 우는데 옆에 어른이 이미 달래고 있는 경우.
유저 입장에서 생각해보면 이 두가지는 UX적으로 아주 중요한 결함입니다.
첫번째 같은 경우, 밤에 자고 있다가 알람을 듣고 깨서 애가 운다고 해서 갔는데 멀쩡하다면 불쾌하게 잠에서 깨고 이 제품에 오류가 많다고 생각하겠죠.
두번째 같은 경우, 역시 알람이 울리지 않아도 되는 경우입니다. 이미 누군가가 애를 달래고 있다면 불필요하게 알람을 할 필요가 없겠죠.
저는 이 문제를 데이터 가이드라인을 바꿈으로써 해결하였습니다.

이렇게 라벨링에서 애매함을 줄여줌으로써 좀 더 품질이 높은 데이터를 쌓을 수 있었습니다. 모델 구조에는 전혀 변화가 있지 않았습니다. 여기서 2,3번 라벨일 경우 전부 애기 울음 아님 데이터에 넣어 불필요한 감지를 줄일 수 있었습니다.
(아기 울음감지 분류 시스템에 대한 자세한 내용은 이 포스트를 참고해주세요)
MLOps: 일관성 있는 질 좋은 데이터를 확보하는 과정

마지막으로 응 교수님은 시스템 런칭 이후의 모델 개발 프로세스에서의 데이터의 중요성을 강조합니다. 한번 학습해서 런칭하면 끝이 아니라 그 이후에도 지속적으로 시스템을 통해 들어오는 데이터를 수집하고 분석해서 다시 모델을 개선하는 등의 사이클이 필요하다는 이야기를 합니다. 여기서도 가장 중요한 것은 질 좋은 데이터의 일관성 있게 확보하느냐가 가장 중요하다고 말합니다.
코드와 런칭된 시스템을 지속적으로 관리하는 DevOps가 소프트웨어 엔지니어링의 메인 분야로 성장했습니다. MLOps는 DevOps와 함께 런칭된 머신러닝 AI 시스템을 관리하는 프로세스를 뜻합니다. 앞서 정의했듯이 AI 시스템 = Code + Data이기 때문에, MLOps는 AI 시스템 개발 사이클의 모든 부분에서 일관성 있는 질 좋은 데이터를 유지하는 것이다 라고 하며 세미나가 마무리됩니다.
MLOps는 AI 시스템 개발 사이클의 모든 부분에서 일관성 있는 질 좋은 데이터를 유지하는 것
아직 이 분야는 갈 길이 멀다는 것을 강조합니다. 데이터에 대한 버젼 컨트롤 등 DevOps에 기초적인 기능조차 아직 걸음마 수준이다보니 많은 기회가 있을 것 같습니다.
간만에 정말 보석 같은 세미나를 찾았습니다. 특히나 제 일상 업무에서 매일 느끼고, 배우고, 고민하고 있는 것들을 앤드류 응 교수님이 잘 정리해주셨다보니 너무나도 감사한 마음이 들었습니다. 더 많은 분들이 이러한 정보를 접할 수 있으면 좋을 것 같아 이 글을 써보았습니다. 제 나름대로의 해석과 경험이 들어가있는 리뷰이다 보니 제가 틀리거나 토론의 여지가 있는 부분이 있을 것이라 생각됩니다. 그렇다면 꼭 피드백을 댓글로 남겨주시길 바랍니다!

Reference



