Week 40 - 내가 말하는 걸 보여줘, DALL-E


주변에 디자이너 친구들과 얘기를 하면 분명 회의에서 원하는 것을 잘 상의하고 말로 정리를 잘했는데, 그걸 비주얼로 만들어 나온 것을 공유하면, 상사가 "아니, 내가 원했던 건 그게 아니고..."하는 경우가 많다고 합니다.
그만큼 글이나 말로 된 언어와 시각적으로 표현된 비주얼 언어에는 큰 차이가 있다는 것을 알 수 있습니다. 근데 그렇게 어려운 걸 NLP이 모델이 해낼 수 있다고 하면 믿으실 수 있겠습니까.
"설명하지 말고 보여줘라! (Show! Don't tell!)"은 주로 좋은 글을 쓰는 방법에 나오는 조언 중 하나입니다. 말로 설명하는 것보다 이야기나 어떤 예시로 보여주는 것이 더 효과적이란 얘기죠.
NLP에서 현재 글을 제일 잘 쓰는 모델은 OpenAI의 GPT-3라는 것은 <위클리 NLP>를 열심히 읽으신 구독자라면 이미 알고 계실겁니다.
근데 이 GPT가 Show! Don't Tell!을 너무 말그대로 받아들였는지 진화를 해버렸습니다. 바로 2021년 1월에 발표된 DALL-E라는 모델입니다. 이 모델은 내가 쓴 글을 그대로 이미지로 생성해냅니다. 얼마나 그걸 잘 하냐고요? 이런건 어떨까요?
"아보카도 모양을 가진 의자"

이번주에는 NLP와 Computer Vision이 혼합된 모델 DALL-E에 대해 알아봅니다.

텍스트에서 이미지로 (TEXT-TO-IMAGE)
지난 Week 24에서 Image-to-Text 문제를 소개했었습니다. 이미지를 보고 이를 설명하는 캡션을 달아주는 모델, 아이에게 그림 책을 읽어줄 수 있는 AI. 이 모델이 처음 나왔을 때 저는 정말 신박하다고 생각했습니다.
Text-to-image는 이것의 정반대입니다.
텍스트를 읽고 이미지를 생성하는 문제. 곰곰히 생각해보면 난이도가 훨씬 더 어려운 문제라는 것을 알 수 있습니다. 어찌보면 인간의 상상력을 넘어야 하는 문제이기 때문이죠. "아보카도 모양을 가진 의자"라는 텍스트를 읽으면 머리 속에 어렴풋이 어떤 그림이 그려지실 것 입니다. 하지만 이를 실제로 종이나 스크린에 비쥬얼로 옮기는 것은 또다른 차원의 능력입니다. 그렇기 때문에 그래픽 디자이너라는 직업이 존재할 수 있겠죠.
하지만 DALL-E는 수많은 이미지와 텍스트 데이터를 통해 text-to-image를 해냅니다.

트랜스퍼 (TRANSFORMER) 복습하기
Week 25에서 소개했던 트랜스포머 모델은 기계 번역을 위해 처음 태어났습니다. 단어를 하나하나 보는 RNN보다 더 효과적으로 Self-attention이라는 원리를 통해 더 빠르고 효과적으로 단어 간의 관계를 학습할 수 있는 모델이죠.
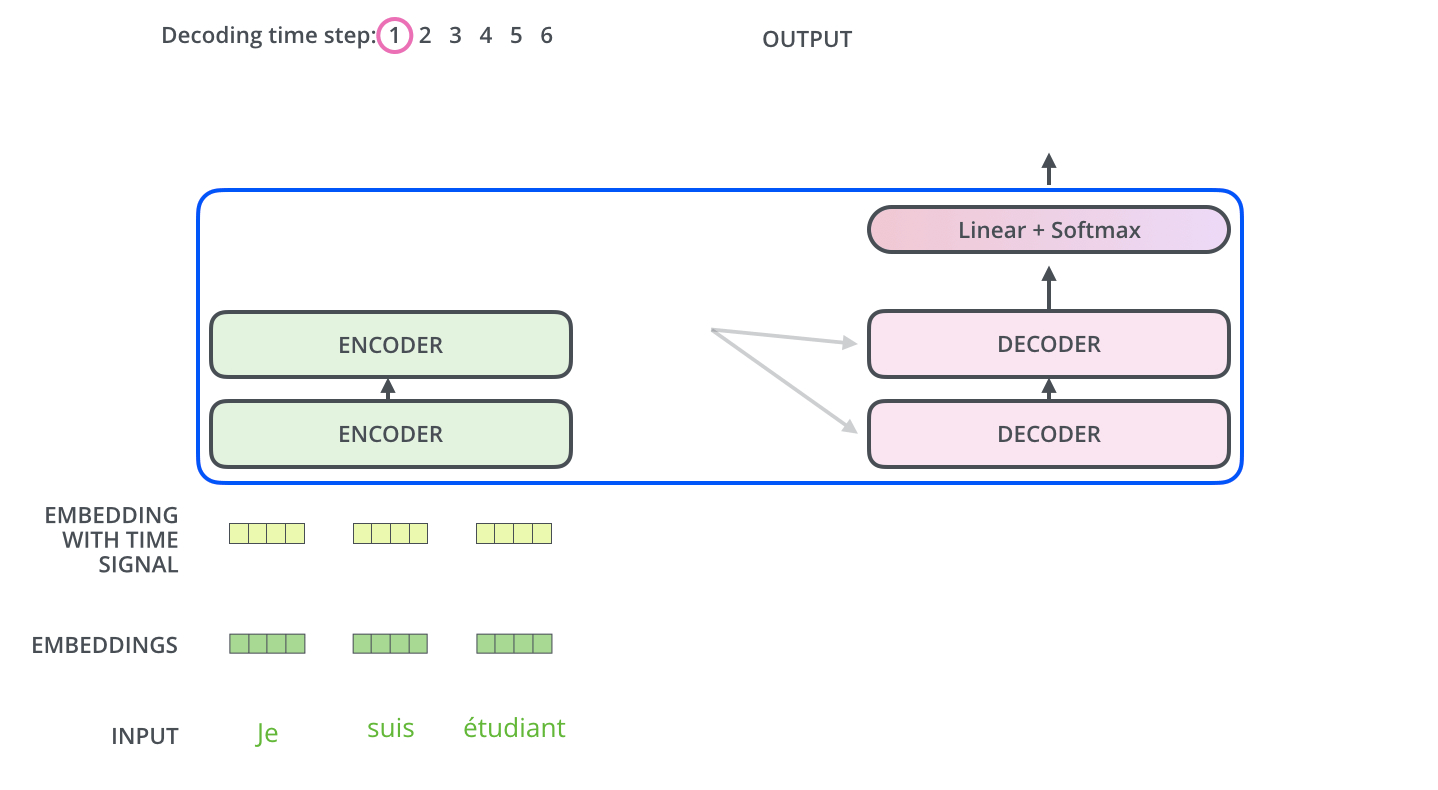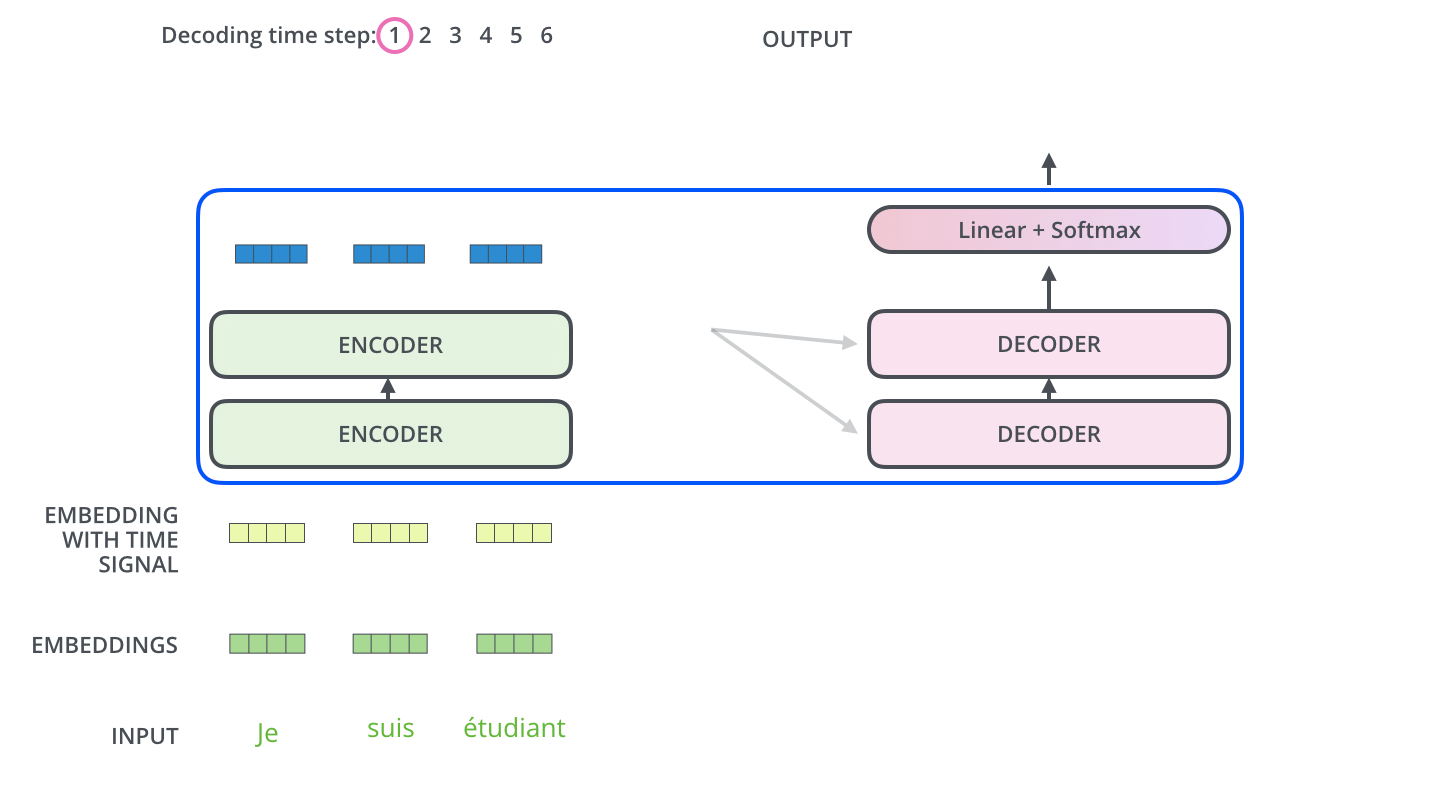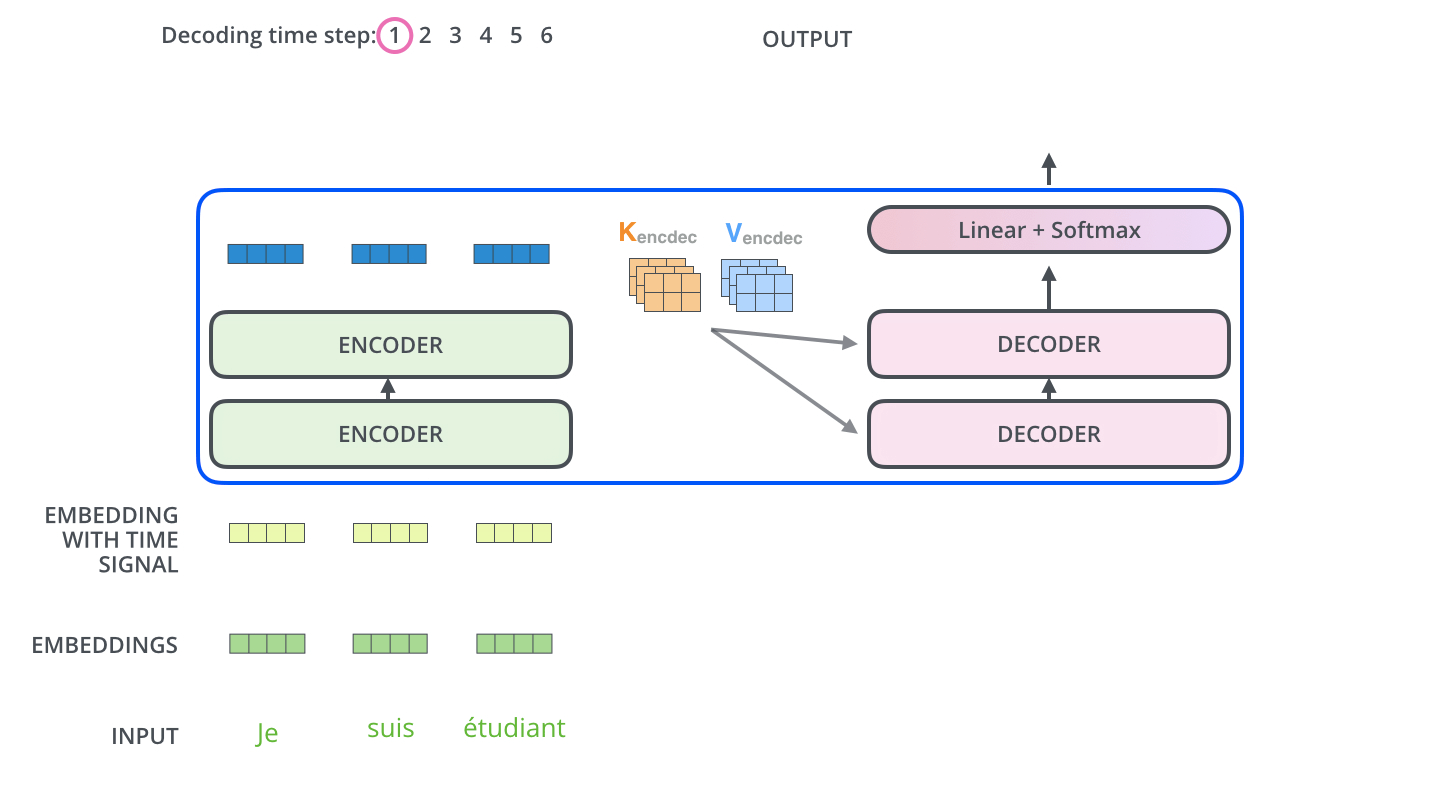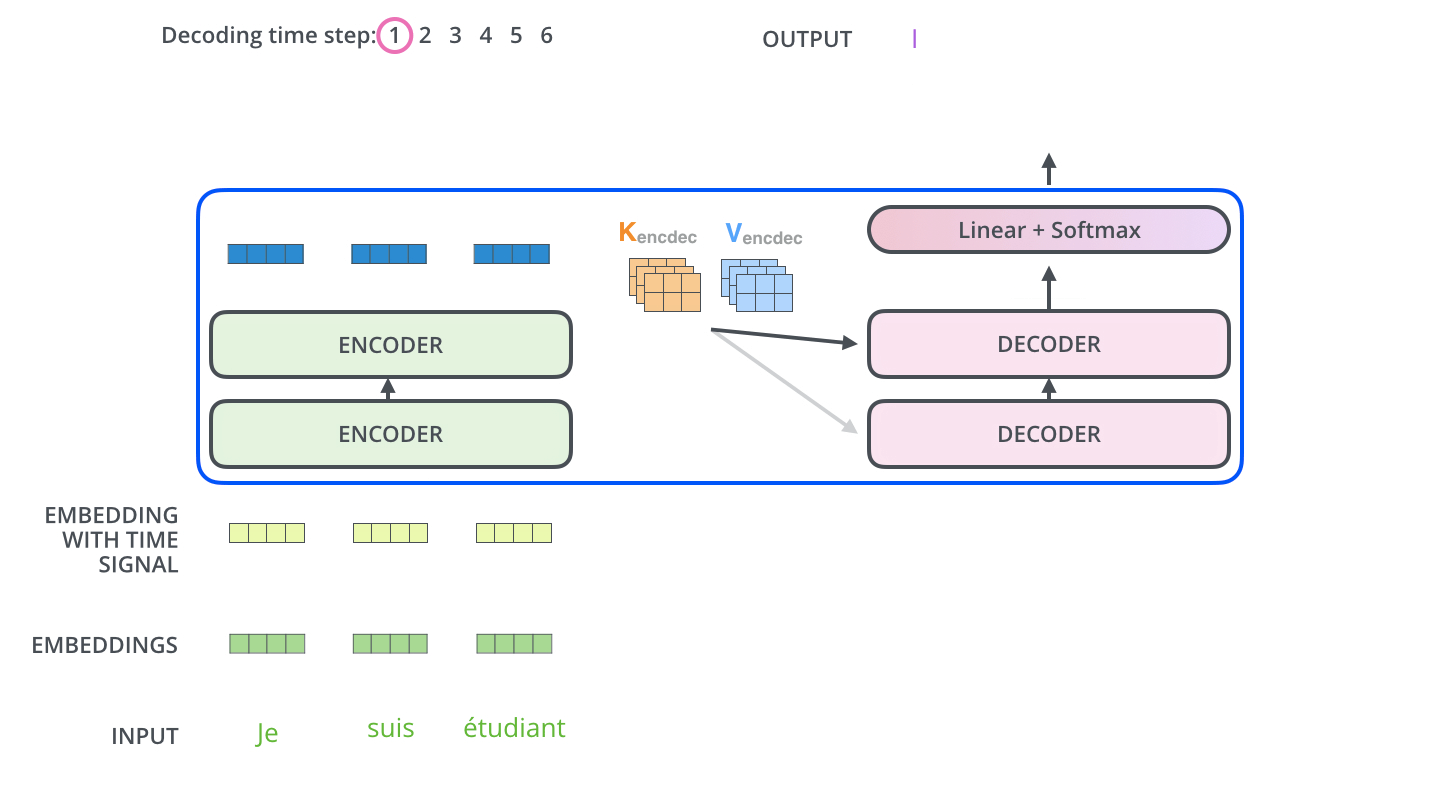
Week 29에서 소개한 GPT는 트랜스포머를 기반으로 한 언어 모델입니다. 기계 번역 모델에서 인코더(encoder) 부분만 떼버린 것이 GPT라고 설명드렸죠. 기계 번역은 한 언어에서 다른 언어로 바꾸어야 하기 때문에 인코더(encoder)-디코더(decoder)가 필요했지만, 언어 모델은 하나의 언어로만 하기 때문에 디코더 트랜스포머만 있어도 충분했습니다.
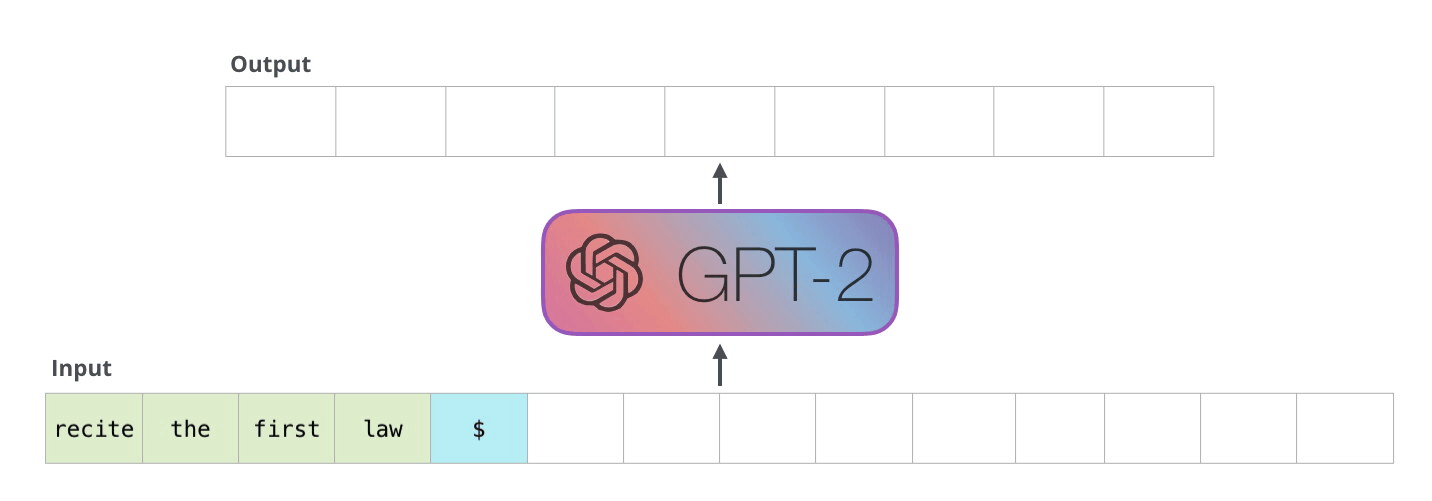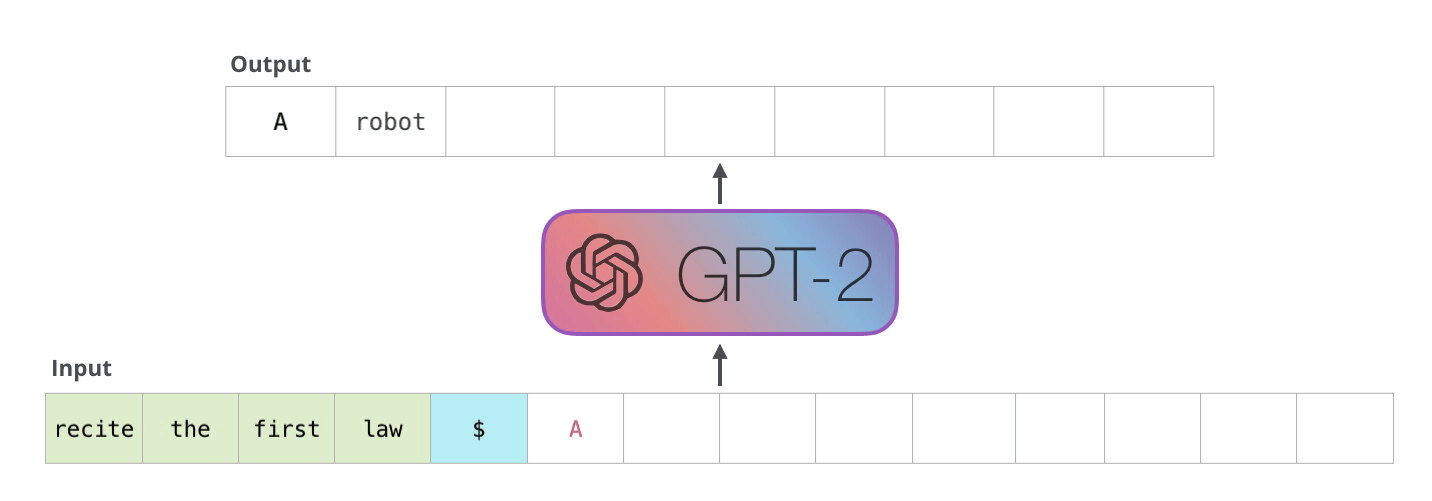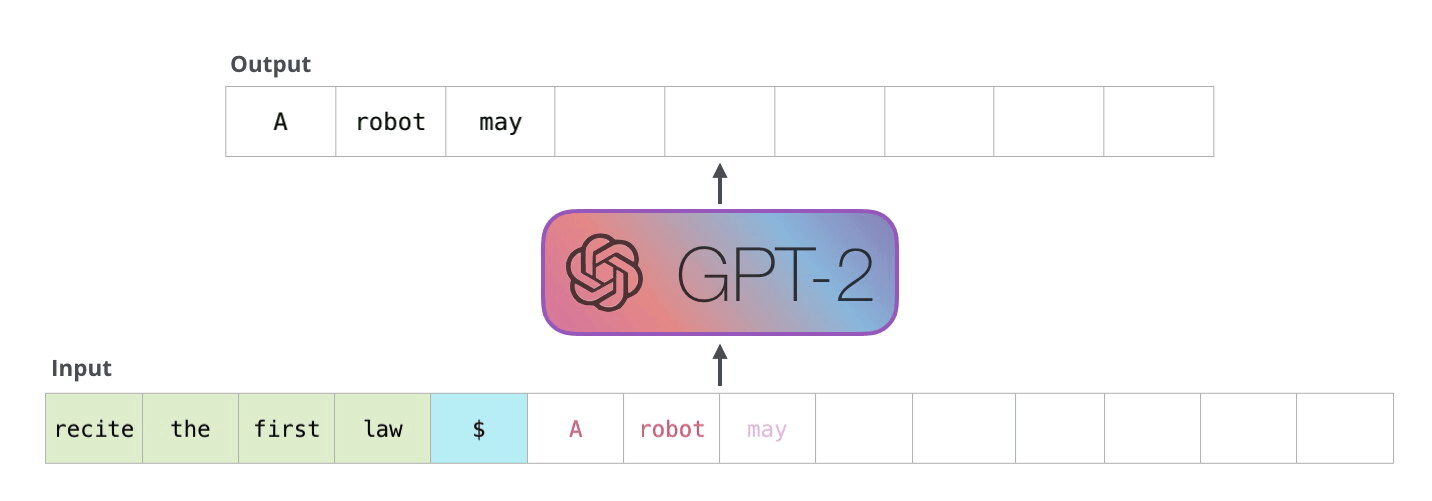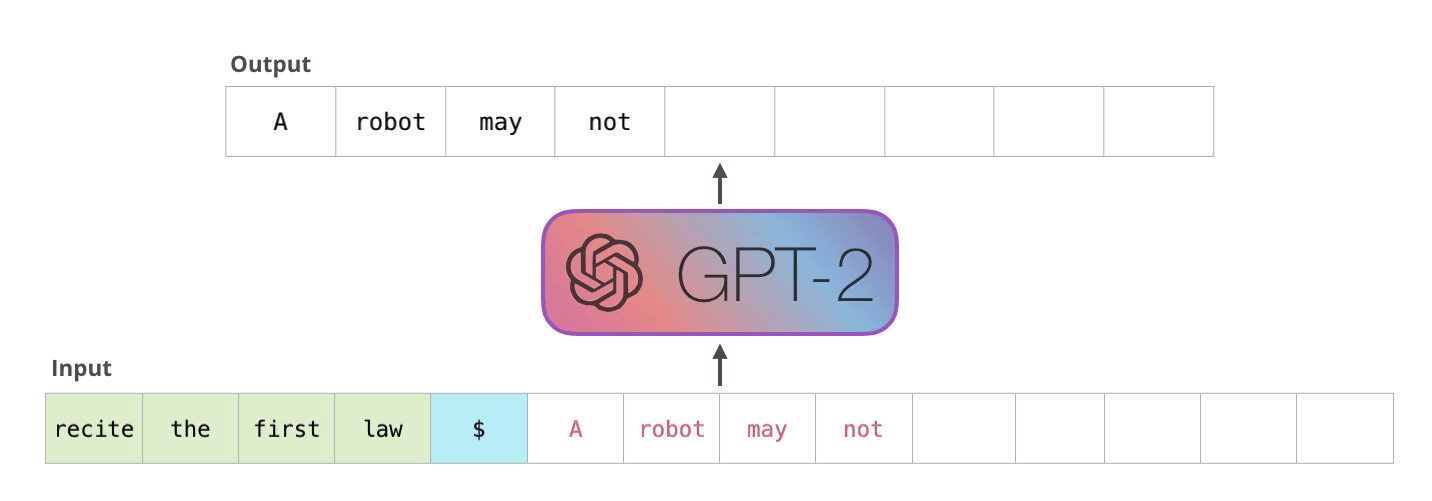
DALL-E의 트랜스포머
DALL-E의 트랜스포머는 GPT-3와 구조가 똑같습니다. 다만 들어가는 데이터의 형태가 다를 뿐이죠. 바로 텍스트 토큰와 이미지 토큰이 함께 하나의 데이터 스트림으로 구성된다는 점이 큰 차이점입니다.
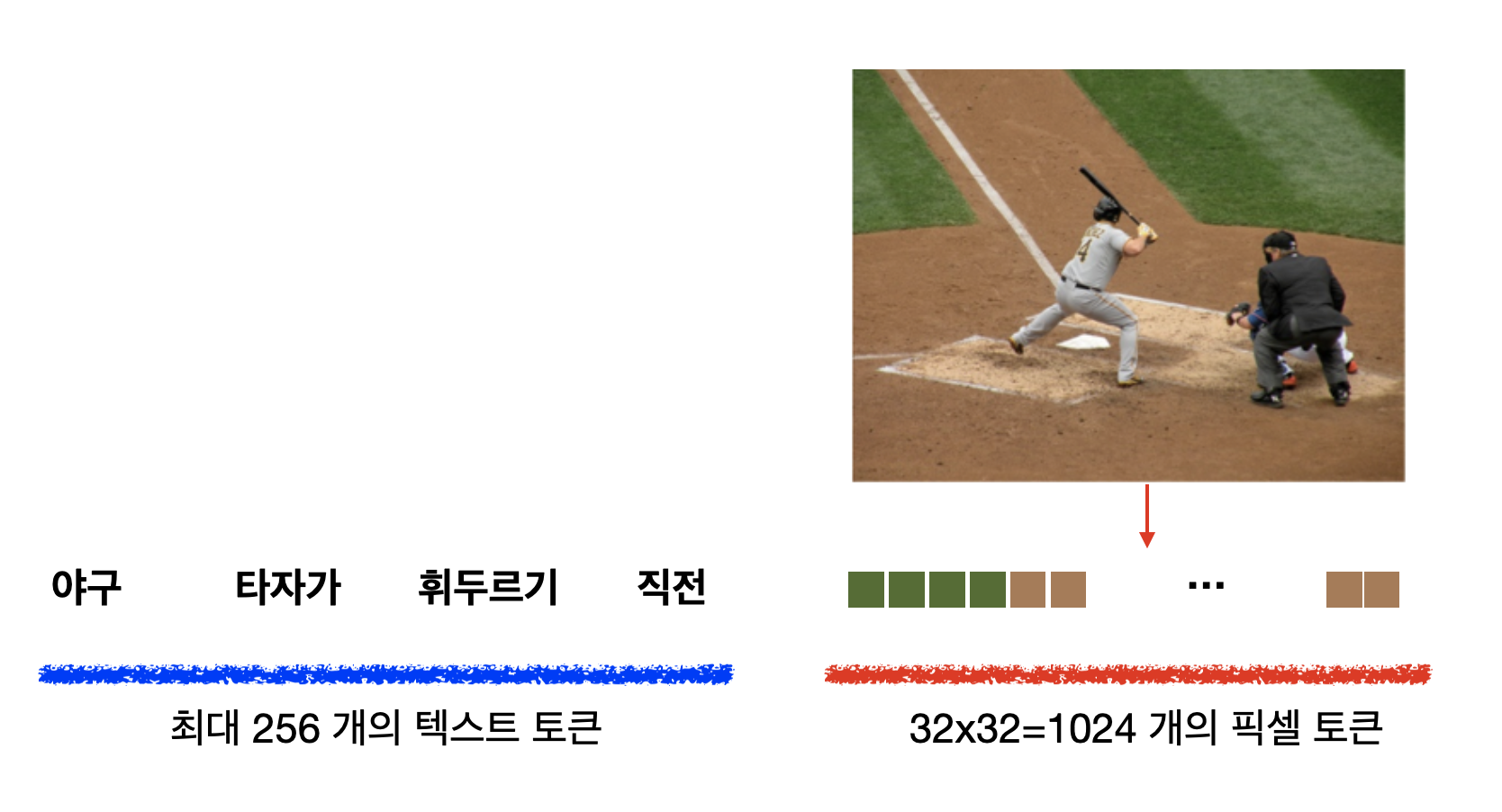
앞에 먼저 텍스트 "야구 타자가 휘두르기 직전"이 텍스트 토큰화 되어 있습니다. 그리고 텍스트 토큰이 다 끝난 다음에는 이미지가 들어갑니다. 여기서 흥미로운 것은 이미지를 펴서 일직선으로 만든다는 점입니다. 예를 들어, 32x32 픽셀로 구성된 이미지는 일자로 펴 1024개가, 마치 한 단어, 한 단어 들어가듯이, 하나의 토큰으로 변환된다는 것 입니다.
이게 무슨 말이냐면 픽셀에 들어갈 수 있는 여러 종류의 RGB 값을 NLP의 언어 모델에서 다음에 나올 수 있는 하나의 단어처럼 취급한다는 것 입니다. 예를 들어,
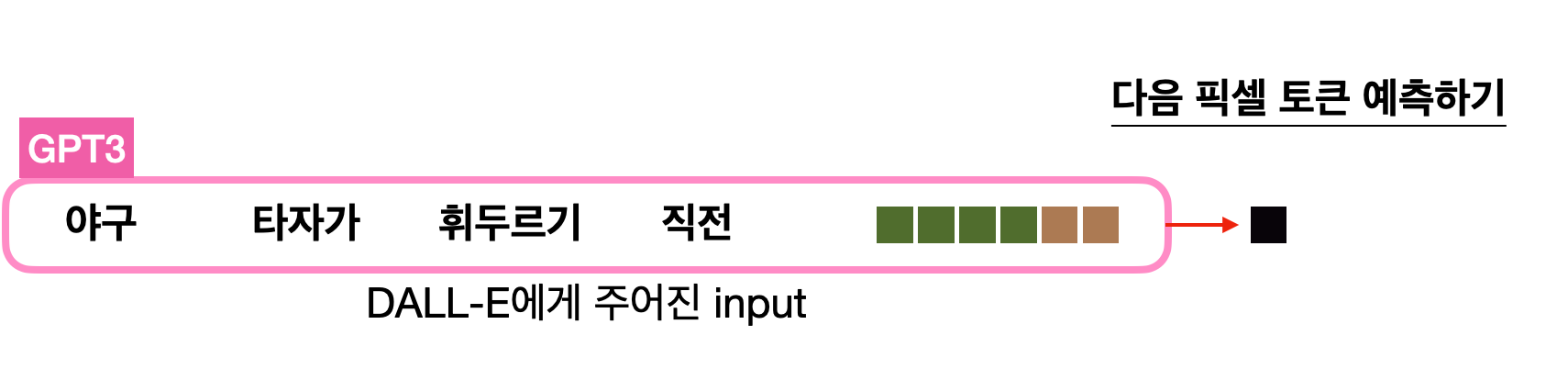
모델은 주어진 텍스트 그리고 여태까지 자신이 예측한 픽셀값들을 전부 고려하여 다음 픽셀이 무엇일지 예측(생성)합니다. 그렇기 때문에 텍스트의 내용과도 연관이 있으면서도 이미지도 제대로 된 형태를 갖출 수 있도록 다음 픽셀을 생성할 수 있게 학습이 되는 것 입니다.
이렇게 한 개 한 개 픽셀을 생성하고나면 마지막에는 이걸 다 이어 붙여 다시 32 x 32의 2D 이미지로 재구성합니다.
*심화: 이미지가 너무 고화질이면 예측해야 하는 픽셀 값이 기하급수적으로 늘어나겠죠. 1024x1024만해도 벌써 2^20입니다. 그렇기 때문에 DALL-E에서는 Discrete Autoencoder라는 다른 모델을 학습시켜 이미지를 압축시키는 과정을 먼저 합니다.
DALL-E 예시
백분불여일견(百聞不如一見), 설명하는 것보다 직접 봐야 이 모델이 얼마나 대단한지 알 수 있습니다.
DALL-E는 위치공간에 대한 패턴을 가진 텍스트도 생성합니다.

세상에 없는 컨셉도 만들어낼 수 있습니다.

자세히 설명하지 않아도 단어에 내포된 의미도 척척 생성합니다.


정말 신기하죠? OpenAI 블로그에 가면 더 많은 결과를 볼 수 있습니다.
DALL-E 이름은 무슨 뜻일까?
제가 보통은 이런 모델들을 소개할 때 이름부터 소개를 하고는 하는데, 이번에는 결과가 너무 인상 깊어서 이름 소개 조차 까먹었습니다.
DALL-E는 미술가 살바도르 달리(Salvador Dalí)와 픽사의 로봇 캐릭터 WALL-E의 이름을 합성해서 지은 것이라고 합니다. 포스트의 대표 사진을 통해 이미 눈치를 채셨을지도 모르겠습니다.
DALL-E의 스케일
DALL-E를 학습시키는데 필요한 데이터는 약 2500만 개의 텍스트-이미지 쌍이라고 합니다. 처음에 330만 개로 시작해봤다가 모델 사이즈도 늘리면서 데이터의 양도 늘렸다고 합니다. 단순히 이미지 뿐만 아니라 이를 설명한 텍스트까지 함께 있어야 하니 이러한 데이터를 구축하는 것도 쉽지는 않았을 것 같습니다. 전부 인터넷에서 모았다고는 하지만요.
최종 모델은 약 120억 파라미터(parameter)를 가진 아주 큰 모델입니다. GPT-3이 1750억 개이니 이에 비해서는 작다고 생각할 수도 있지만, 여전히 어마어마한 사이즈입니다. 원 논문에는 GPU 분산 트레이닝에 관한 내용도 나와있으니 관심있으시면 참고하시길 바랍니다.
DALL-E는 공개되어 있는가?
아쉽게도 OpenAI는 더이상 전처럼 오픈하지 않습니다. 이 모델은 오픈소스로 공개되어 있지 않습니다. GPT-3처럼 상용화를 준비하고 있지 않나 조심스럽게 예상해봅니다. 다만, 이 모델은 그렇게 복잡하지 않기 때문에 직접 구현하는게 어렵지는 않을 것 같습니다. 물론 많은 데이터와 큰 모델을 돌릴만한 GPU는 알아서 준비해야겠지요.
DALL-E의 활용 방법?
OpenAI의 블로그에서는 패션이나 실내 인테리어 디자인에서의 활용 가능성을 염두로 둔 예시를 보여주고 있습니다만, 아직까지는 구체적인 어플리케이션은 나와있지 않습니다.
디자이너들의 창의력에 좀 더 영감을 불어 넣어줄 수 있는 툴이 될 수 있을까요? 아니면 템플릿으로 간단한 패턴이 있는 디자인들은 DALL-E로 생성하는 날이 올까요? 혹시 떠오르는 아이디어가 있으시면 댓글로 남겨주세요!
아직 저화질의 이미지 밖에 생성하지 못한다는 점, 생성된 이미지가 바로 쓰이기에는 퀄리티가 아쉽다는 점 등 상용화에는 보완해야 할 것이 있어 보입니다.

오늘은 OpenAI가 또 한번 세상을 놀래킨 Text-to-Image 모델 DALL-E에 대해서 알아보았습니다. 이처럼 여러가지 형태의 인풋을 혼합한 모델을 멀티 모달(Multi-modal)이라고 합니다. 이 연구는 NLP와 Computer Vision의 기술이 융합되어 엄청난 것이 나온 예시라고 할 수 있습니다. 지난 Google I/O 리뷰에서 소개한 MUM 역시 멀티 모달 방식의 기술입니다.
제가 요즘에 이러한 NLP + ? 의 멀티 모달 연구에 관심이 많아져 이것저것 보고 있는 중인데, 앞으로 몇 개의 글은 시리즈처럼 연재해보려고 합니다. DALL-E는 이 멀티모달 시리즈의 좋은 스타트라고 생각하여 소개해보았습니다.

REFERENCE
- DALL·E: Creating Images from Text, OpenAI Blog
- Ramesh et al., 2021, Zero-Shot Text-to-Image Generation



