Week 44 - 하나의 문장을 언어학적으로 해부해볼까: DP, POS, NER


여러 문장이 모여 문단이 되고, 문단이 모여 글이 됩니다. 우리는 매일 같이 다양한 글을 읽는데, 하나의 문장은 어떻게 구성되어 있는지 생각을 하고 읽지는 않습니다. 그렇게 된다면 독서는 굉장히 피곤한 활동이 되겠죠. 이처럼 인간은 문장을 보자마자 즉시 구조를 파악하고 중요한 키워드를 뽑아 내는 능력을 가졌습니다. 이 두 가지는 문장의 의미를 이해하는데 굉장히 중요합니다.
NLP 모델은 어떨까요? 앞서 공부했던 GPT, BERT 같은 거대 언어 모델들은 사람과 비슷하게 문장의 구조와 핵심을 파악해 해야 하는 예측을 효과적으로 잘 합니다. 하지만 그 중간에 어떤 생각 단계를 거쳐 이 예측 결과가 나오게 되었는지 분석하는 것은 쉽지 않습니다. 딱히 분석이 없어도 최종 예측만 잘하면 되니깐요.
하지만 하나의 문장에 대한 언어학적 분석이 꽤 유용할 때가 많다는 것 알고 계셨나요? 어떤 식으로 분석하는 것이 가능할까요?
이번 글에서는 하나의 문장의 구조와 핵심을 파악하는 언어학적 분석 방법 세 가지를 소개하도록 하겠습니다.
1) 의존 구조 분석 (Dependancy parsing),
2) 품사 분석 (Part-of-Speech tagging),
3) 개체명 인식 (Named Entity Recognition)
그리고 마지막에는 이러한 분석 결과가 어떻게 여러 문제에 응용되는지도 알아보도록 하겠습니다.

DEPENDENCY PARSING (의존 구조 분석)
의존 구조 분석이란, 문장의 구조를 파악하는데 유용합니다.
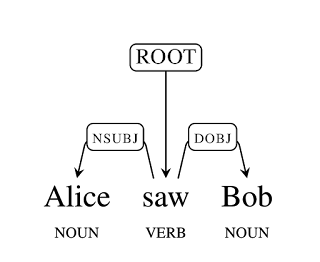
이처럼 하나의 문장은 대부분 주동사(ROOT) 위주로 이루어지고, 주어(nsubj)와 목적어(dobj)로 나누어집니다. 이 두 개는 보다(봤다)라는 주동사에 의존하는 부분이라고 볼 수 있습니다. 참 쉽죠?
그런데 우리의 언어는 그렇게 간단하지가 않습니다. 궁금한 점이 많기에 문장이 길어지는 경우가 많습니다. Alice는 무엇을 하고 있으며, Bob을 어디서, 언제 봤는지 알고 싶습니다.
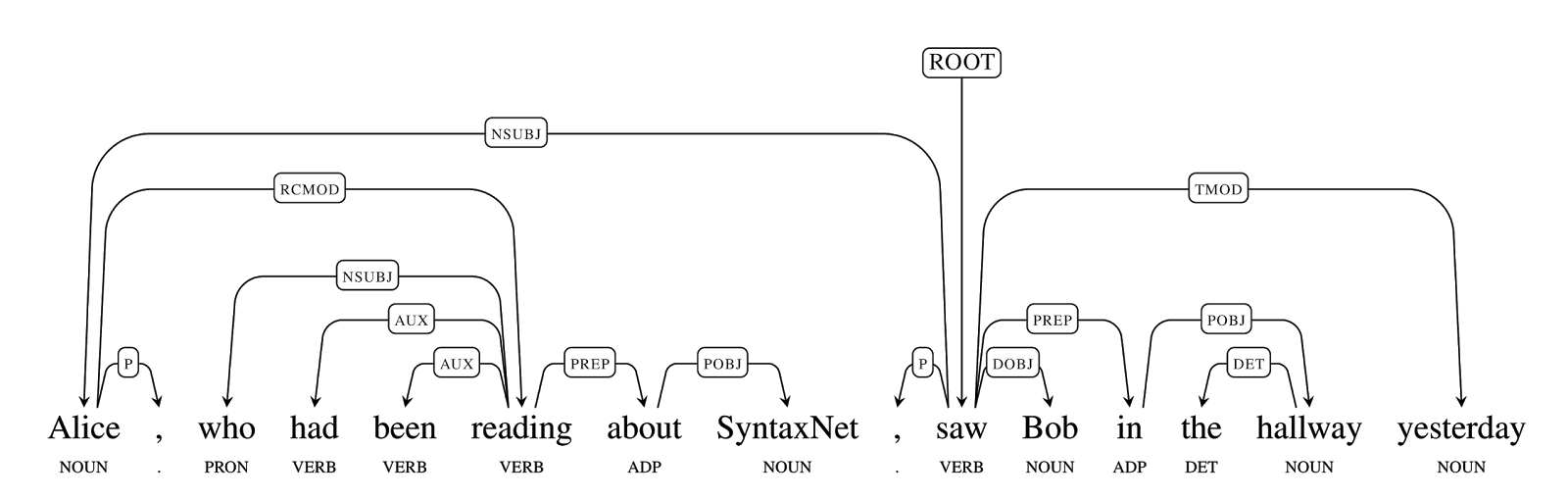
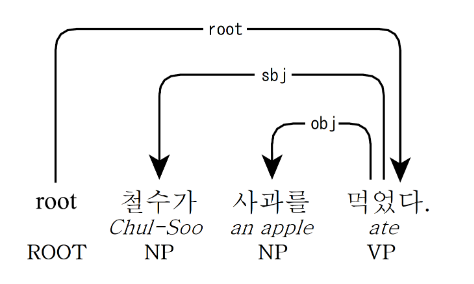
그렇기에 의존 구조가 이렇게 복잡해질 수도 있습니다. 한국어의 경우는 어떨까요? 이 그래프를 보시면 한국어 역시 의존 구문을 분석할 수 있다는 것을 알 수 있습니다.

이러한 그래프를 생성하기 위해 어떤 모델이 학습해야 할까요? 여러 연구가 진행되고 있지만, 이 문제에 가장 좋은 성능을 보이는 연구를 정리한 이 웹사이트를 보면 Attention Mechanism (관심법)에 의한 모델이 가장 효과적이라는 것을 알 수 있습니다.

POS TAGGING (품사 분석)
Part-of-Speech(POS) Tagging이란, 문장이 주어졌을 때 각 단어들이 어떤 기능을 하는지 나타내는 품사를 태그하는 문제입니다. 쉽게 말하면 문장의 단어들을 명사, 대명사, 동사, 형용사, 부사 등 문법적인 분류로 나누어 문장을 이해하는 작업입니다. 위의 의존 구조 파악과 함께 사용하고는 합니다.
POS Tagging은 전형적인 Sequence Labelling문제이기 때문에, LSTM 같이 단어를 컨베이어 벨트처럼 보는 RNN 모델이 좋은 성능을 보입니다.

NAMED ENTITY RECOGNITION (개체명 인식)
개체명 인식은 말그대로 알려진 개체를 문장에서 인식하는 문제입니다. 가장 대표적으로 사람/단체/장소 이름을 문장 속에서 뽑아내는 것이죠. 여기서 어려운 점은 단순히 알려진 이름들을 DB에 저장해놓고 매칭시키는 것이 아니라 새로운 이름이 나타났을 때도 어떤 카테고리인지 유추해야 한다는 점입니다.
더 나아가서 각종 수량 정보 역시 NER의 범주 내에 들어갑니다. 특히 날짜는 캘린더 기능을 다루는 AI 비서 시스템에게는 굉장히 중요한 내용이기 때문에 NER을 통해서 모델에게 추가 인풋 정보로 사용하는 경우가 있습니다. 그 외에도 돈, 시간 등 다양한 수량 카테고리가 유용하게 쓰일 수 있겠죠.

언어학적 분석은 어떻게 쓰일까?
의존 구존 분석과 POS Tagging은 문장의 구조와 단어 간의 관계를 파악하는데 중점을 두고 있습니다. 언어학자들이 만든 이론에 따라 NLP 모델을 이용해 문장 분석을 하는 것이죠. 재밌는 사실은 RNN, BERT, GPT 등의 언어 모델에서는 이러한 지식을 직접적으로 가르켜주지 않아도 어느정도 네트워크 안에 파악이 되어있다는 것입니다.
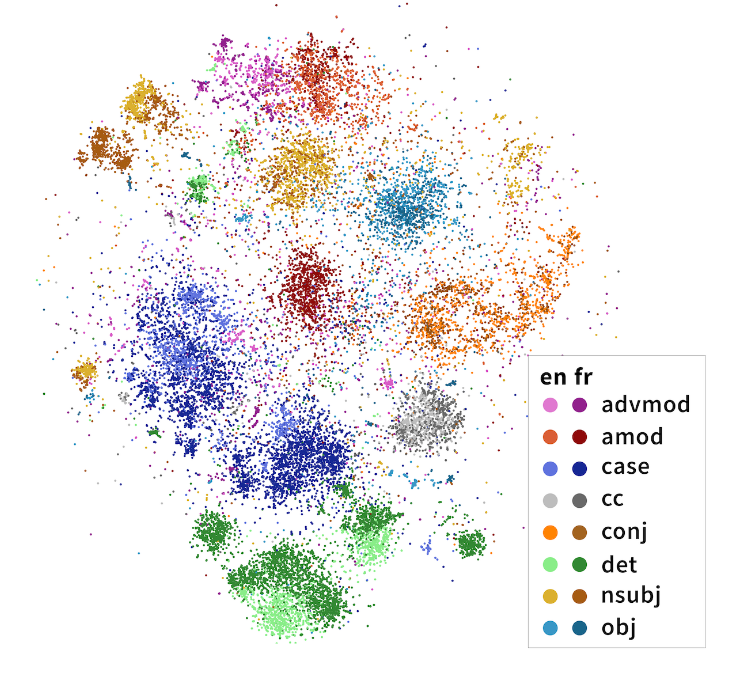
2020년 발표된 이 논문에서는 여러 언어 데이터가 함께 학습된 다국어 mBERT 모델을 분석한 결과, 문장의 의존 구조를 어느 정도 파악하고 있는 것으로 나타났습니다. 더 재밌는 점은 만국 언어 공통의 구조 역시 존재하고, 비슷한 언어 계열일 경우 이 구조가 공유될 수 있다는 점입니다.
예를 들어, 영어 데이터만으로 BERT를 학습해도 프랑스 문장 구조에 대한 이해가 있다는 것이죠. 다국어(multilingual) 모델은 또 하나의 재밌는 주제인데, 다음에 한번 다루어보도록 하겠습니다.
이렇게 대형 언어 모델들이 있음에도 불구하고 우리는 왜 오늘 소개된 세 가지 언어학적 분석에 대해서 알고 있으면 좋을까요?
1) 속도나 데이터의 한계로 대형 언어 모델을 사용하지 않는 경우
2) 이러한 언어학적 분석 결과가 다른 문제 해결에 도움되는 인풋이 되는 경우
정보 추출(Information Extraction)
언어 모델 그대로는 글에서 정보 추출하는데 적합하지 않습니다. 다음 단어가 무엇인지 예측하기 위해 만들어진 모델이기 때문이죠. 이를 위해서는 언어 모델을 추가로 학습시켜 Question & Answering 모델로 만드는 방법이 있습니다. 하지만 QA 모델은 질문과 답의 쌍으로 이루어진 많은 학습 데이터가 필요합니다. 그리고 주로 모델의 크기가 커야 제대로 된 성능을 보이기 때문에 모든 경우에 적합하다고 할 수는 없습니다.
그에 반해 오늘 배운 문제를 위해 학습된 모델들은 좀 더 작은 모델 사이즈와 빠른 추론 속도를 보여줍니다. 그렇기 때문에 수많은 데이터에서 빠르게 원하는 정보만 추출하기에 매우 적합하죠.
예를 들어 개체명 인식을 사용한다면 수많은 데이터 중에 사람 이름이 들어간 문장만 추출할 수 있습니다. 아니면 다른 것은 다 필요없고 주동사와 명사만 뽑아내고 싶다면 의존 구조 분석기와 POS 태깅 모델을 사용할 수 있겠습니다.
이렇게 데이터에서 필요한 부분만 빠르게 뽑아낼 수 있기 때문에, 키워드 기반, 토픽 기반 문제에 유용하게 쓰일 수 있습니다. 뉴스 기사 추천, 제품 정보 추출, 토픽 모델링(topic modeling)처럼 문장의 전체보다는 관심 키워드가 중요한 문제들에 주로 응용됩니다.
피쳐(Feature)로 활용하기
문장에서 단어들이 어떤 의존 구조를 가지고, 각 단어가 어떤 POS 태그를 갖고 있고, 어떤 키워드가 문장에 포함되어 있는지는 무척 중요한 신호입니다. 예를 들어, AI 비서에게 말하는 문장에 장소 이름이 있다면 지도 검색에 관련될 확률이 높을 것이고, 아티스트의 이름이 있다면 미디어 재생과 관련된 기능을 이야기할 확률이 높겠죠.
학습 데이터가 많이 없을 때 또는 대형 언어 모델 같이 미리 많은 양의 데이터로 학습된 모델을 활용할 수 없을 때에는 이런 언어학적 분석이 유용한 정보일 수도 있습니다. 그럴 때 의존 구조, POS 태그, 확인된 개체명을 다른 모델의 인풋 피쳐(input feature)로 넣어주는 방식은 성능 향상에 도움이 될 수도 있습니다. 본 모델에 언어학적 외부 지식을 주입해주는 것이라고 생각하시면 됩니다.
최근 카카오엔터프라이즈 음성 팀에서 발표한 논문에서 개체명과 POS 태그 정보를 이용해서 사족 제거(disfluency detection)의 성능을 높인 것이 아주 좋은 예시입니다. 사족 제거란 유저가 말을 할 때 "음..", "아니" 같은 불필요한 단어나 버벅임 때문에 반복되는 단어를 지워 좀 더 깔끔한 문장으로 변환해주는 문제인데요. 이러한 모델을 학습할 때 언어학적 신호도 함께 학습하는 방식으로 기존의 연구보다 좋은 성능을 이루어냈다고 합니다.

어떻게 사용할 수 있을까?
그렇다면 이러한 모델은 어떻게 사용할 수 있을까요?
가장 흔한 방법은 오픈소스를 이용하는 방법입니다. 영어일 경우 유명한 라이브러리인 nltk, spacy 같은 라이브러리가 있고, 한국어의 경우 konlpy, Pororo 등이 있습니다 (다른 추천 라이브러리가 있다면 댓글로 알려주세요!)
다른 방법으로는 상용화된 API를 활용하는 방법입니다. 예를 들어 구글 클라우드에선 이러한 문장 분석 기능을 다양한 언어에서 제공하고 있습니다. 다만, 일정 콜 이후에는 유료가 된다는 단점이 있습니다.
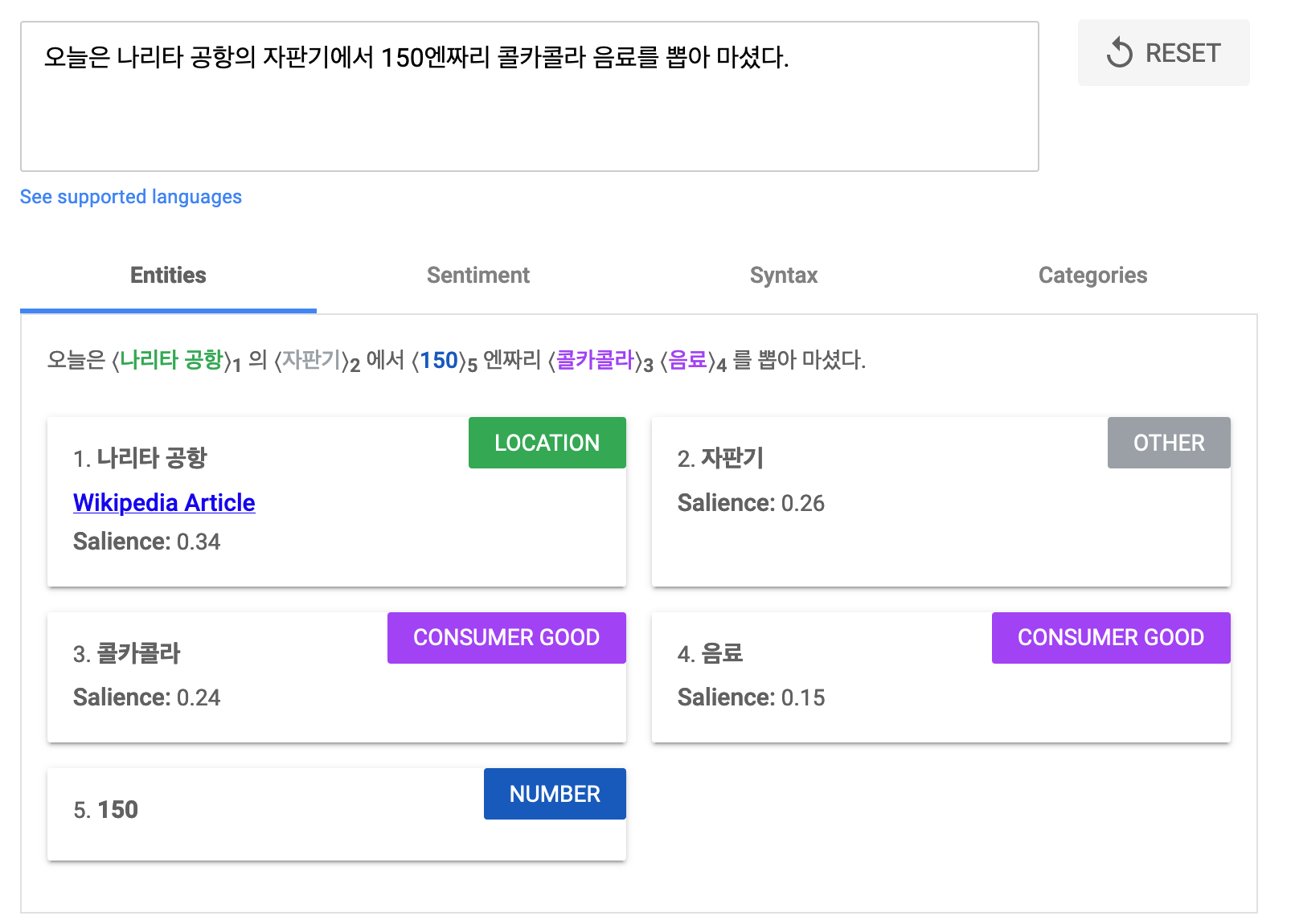
*저는 업무용 때문에 비슷한 서비스를 사내에서 이용하고 있는데, 무척 잘 쓰고 있습니다! 물론 이는 제 개인적인 의견이고, 저는 구글 클라우드와는 관련없다는 것을 알려드립니다. ^^
마지막으로는 직접 학습 시키는 방법입니다. 지난 번에 다룬 KLUE에 데이터 셋이 있으니 모델 학습에 직접 도전해보시는 것은 어떨까요?

오늘은 좀 더 "언어학자"스러운 주제인 의존 구존 분석, 품사 분석, 그리고 개체명 인식에 대해서 알아보았습니다. 딥러닝 세계에서 인기가 많은 주제는 아니지만, 실제 NLP를 응용하여 어떤 문제들을 풀 때 이러한 언어학적 분석을 많이 이용하기 때문에 한번은 짚고 넘어가야겠다고 생각하였습니다. 혹시 현재 풀려고 하는 문제 또는 전에 다루었던 문제에 이러한 것들을 이용했다면 댓글로 알려주세요!
REFERENCE
- Chapter 8: Sequence Labeling for Parts of Speech and Named Entities; Chapter 14: Dependency Parsing, Speech and Language Processing. Daniel Jurafsky & James H. Martin
- Chi et al., 2020, Finding Universal Grammatical Relations in Multilingual BERT
- Lee et al., 2021, Auxiliary Sequence Labeling Tasks for Disfluency Detection, Interspeech 2021
- KLUE: Korean Language Understanding Evaluation




