Week 53 - GPT3는 어떻게 강화학습(RL)으로 강해졌는가


최근 스타워즈와 마블 영화를 정주행하며 공통적으로 느끼는 점이 있습니다.
- 인간이 어떤 강력한 기술 또는 무기를 가진다는 것은 많은 문제를 일으킨다.
- 이 문제로부터 흥미진진한 스토리가 시작된다.
- 괴물 같은 힘을 다스리기 위해 더 많은 노력을 해야 하고, 잘 안된 경우 힘에 잡아먹히면서 소유권이 바뀐다. 그리고 그렇게 그 인간은 빌런이 된다.
GPT, LaMDA 등 그동안 수많은 거대 언어 모델을 공부해보면서 이 NLP 모델들의 강력함 뿐만 아니라, 한계점과 리스크까지 계속 다루고 있습니다.
최근 몇 년간 OpenAI와 구글은 각각 강력한 컴퓨팅 파워로 모델 사이즈를 거대하게 늘리고, 인터넷을 통해 빅데이터를 모아 강력한 NLP 모델을 학습시켰습니다.
역시나 퍼포먼스는 엄청납니다. 거의 사람 수준으로 NLP 문제를 풀 수 있습니다. 하지만 많은 후속 연구를 통해 이 모델들도 아직은 완벽하지 않고 정제가 필요하다는 것이 밝혀지고 있습니다. 그렇기에 이제는 이 괴물들을 잘 조련시켜 유용하게 쓰는 방법에 대한 연구가 계속되고 있습니다.
지난 번에는 LaMDA를 다루었다면, 이번에는 OpenAI에서 2022년 3월에 공개한 논문 Training language models to follow instructions with human feedback을 리뷰합니다.
이 연구는 강화학습(reinforcement learning)을 사용했다는 큰 특징인데요. GPT-3가 어떻게 강화학습으로 더 강해졌는지 알아보도록 하겠습니다.

GPT, 뭐가 문제인데?
Generative Pretrained Model을 뜻하는 GPT는 OpenAI에서 버젼 1, 2, 3까지 나온 거대한 언어 모델입니다. 언어 모델인만큼 어떤 텍스트가 주어졌을 때, 다음 텍스트가 무엇인지 예측하며 인간만큼 논리정연한 글을 생성할 수 있다는 점이 세상을 놀래켰었지요.
그리고 풀고 싶은 문제를 GPT에게 직접 말로 풀어서 설명하거나 예시를 주는 방식으로 Q&A, 번역, 코드 생성, 패턴 맞추기 등 더 다양한 응용 사례를 만들 수 있었습니다. OpenAI는 GPT-3를 사람들에게 API로 제공하면서 점점 더 많고 다양한 곳에 거대 언어 모델이 이용되고 있습니다.
다만, 공개가 된 후 점점 더 많은 사람들이 GPT를 이용하면서 문제점도 많이 발견되었습니다. OpenAI는 이러한 피드백을 기반으로 후속 연구를 진행하였고, 최근에 API의 기본 모델을 새 모델인 InstructGPT로 업데이트했다는 발표를 하며, 이에 대한 논문도 공개하였습니다.
OpenAI에서는 기존 GPT의 큰 문제점을 3가지로 정의하였습니다.
1. Untruthful (거짓)
2. Toxic (해로움)
3. Not helpful (도움이 안됨)
*GPT가 생성하는 모든 텍스트가 이렇다는 것이 아니라 잘못된 경우에 국한된 특징입니다.
논문에서는 “models aren’t aligned with their users”, 즉 유저가 원하는 방식으로 행동하지 않는 것이 가장 큰 문제라고 보았습니다. 아래 예시를 볼까요.

예시를 보면 기존의 GPT-3는 유저의 의도를 무시하고 비슷한 문장만 생성합니다. 전혀 유용하지가 않죠.
반대로 업데이트된 InstructGPT는 유저의 지시를 잘 받아들이고 올바른 답변을 생성해낼 수 있습니다.
GPT는 원래 이러한 지시를 따르기 위해 학습된 것이 아니라, 인터넷에서 수집된 텍스트로 학습되었기 때문에 항상 주어진 지시에 맞추어 유저의 의도대로 생성하지 않을 수 있다는 점을 논문에서는 강조합니다. 그렇다면 이를 극복하기 위해서는 어떻게 해야할까요?
(언제나 그렇듯이) 먼저 해야 할 일은 바로 추가로 학습 데이터를 모으는 것입니다.
GPT에게 방과 후 쪽집게 과외를 시켜보자
먼저, GPT에게 추가 학습을 하기로 합니다. LaMDA에서 한 것처럼 학습을 두 가지로 나눕니다.
- Pretraining: 대규모 인터넷 데이터로 학습.
- Finetuning: 따로 수집된 추가 데이터로 학습.
Finetuning을 위해 40여명의 엄선된 크라우드워커(crowdworker)를 고용하여, 사람이 GPT인 척 시뮬레이션한 데이터를 모읍니다. 좀 더 유저의 의도에 맞게 유용한 답변을 생성할 수 있도록, 사람이 작성한 예시를 가지고 직접 모델의 파라미터를 변형하며 학습합니다. 특히 실제 유저들이 API를 통해 제공한 input 중에 개인정보가 없는 데이터를 샘플하여, 크라우드워커들에게 주었다고 합니다.

이렇게 10,000여쌍의 데이터를 모아, GPT를 추가 학습(finetuning)시켰습니다.
답변에 랭킹/점수 매기기
그리고 두번째로 모은 데이터는 GPT가 생성한 답변 후보 여러 개에 크라우드워커들이 점수를 매기는 것입니다. 여러 답변 후보 중에 무엇이 더 좋은 답변인지 랭킹을 매겨 점수화를 하는 방식으로 진행되었습니다.
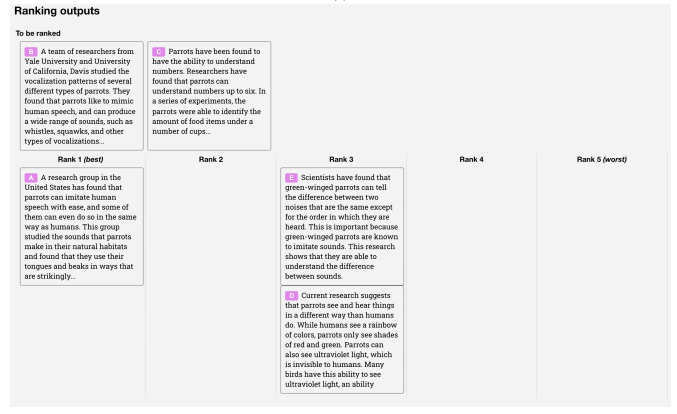
이는 GPT에게 어떤 것이 더 좋은 답변인지 점수를 통해 피드백을 주기 위함인데요. 여기서 가장 큰 문제점은 GPT가 무엇을 생성할 때마다 매 번 사람이 개입하기에는 너무 큰 시간과 비용이 든다는 점입니다.
이를 해결하기 위해 OpenAI는 점수를 예측하는 또다른 모델을 학습시킵니다. 이 모델은 앞서 사람이 점수를 매긴 데이터를 통해 어떤 것이 질이 좋은 답변인지 일반화하여 이 과정을 자동화하려 합니다.
이를 리워드(Reward) 모델이라고 부릅니다.
강화학습(RL) “아주 작게” 뽀개기
강화학습(reinforcement learning; RL)은 머신러닝의 큰 줄기 중 하나로써, 독특한 학습 프레임워크를 가지고 있습니다. 이 글에서 RL 개념을 전부 다루기에는 너무 방대하지만, 이해를 위해 아주 작게 뽀개고 가려고 합니다.

- Agent: 학습하려는 모델
- Environment: 주변 환경
- Action: 모델이 할 수 있는 행동
- Policy: 모델이 어떻게 행동할지 결정하는 알고리즘
- Reward: 모델이 한 행동에 따라, 환경에 따라 주는 리워드.
- Interpreter: 리워드를 결정하는 사람 또는 시스템
즉 RL은 Agent가 Environment와 Action과 Reward를 통해 소통하며 최적의 Policy를 찾는 것이라고 생각할 수 있습니다.
*RL에 대해 깊게 공부를 하고 싶으시다면 Richard Sutton 교수님의 Reinforcement Learning: An Introduction 추천합니다. 대학원생 시절에 재밌게 정주행한 기억이 있습니다.
GPT + RL
그렇다면 GPT를 RL 프레임워크에 놓고 생각해볼까요.
- Agent: 학습하려는 모델 => GPT
- Environment: 주변 환경 => 유저의 input
- Action: 모델이 할 수 있는 행동 => 답변 생성
- Policy: 모델이 어떻게 행동할지 결정하는 알고리즘 => GPT의 파라미터
- Reward: 모델이 한 행동에 따라, 환경에 따라 주는 리워드 => Reward 모델의 예측 점수
- Interpreter: 리워드를 결정하는 사람 또는 시스템 => Reward 모델
GPT 개선의 마지막 단계로, 추가 학습(finetuning)된 GPT에게 또 여러 유저 인풋을 주고, Reward 모델과 함께 인터랙션을 하며 강화학습을 시킵니다.
GPT 모델이 답변 생성을 하면 이를 리워드 모델을 통해 좋은지 아닌지 평가하고, 이러한 피드백을 통해 GPT가 자기 자신을 업데이트합니다. 이런 과정을 계속 반복하여 점점 더 GPT 모델이 “강화"됩니다.
*이때 사용되는 학습 방법은 Proximal Policy Optimization(PPO)라는 방식인데, 더 깊게 들어가지는 않겠습니다. Open AI Gym 등 RL 연구로 이미 유명한 OpenAI RL 연구 팀에서 가장 많이 사용하는 학습 방식이라고 합니다.
OpenAI 블로그에서 제가 여태까지 설명한 것을 깔끔하게 정리해 놓았습니다:
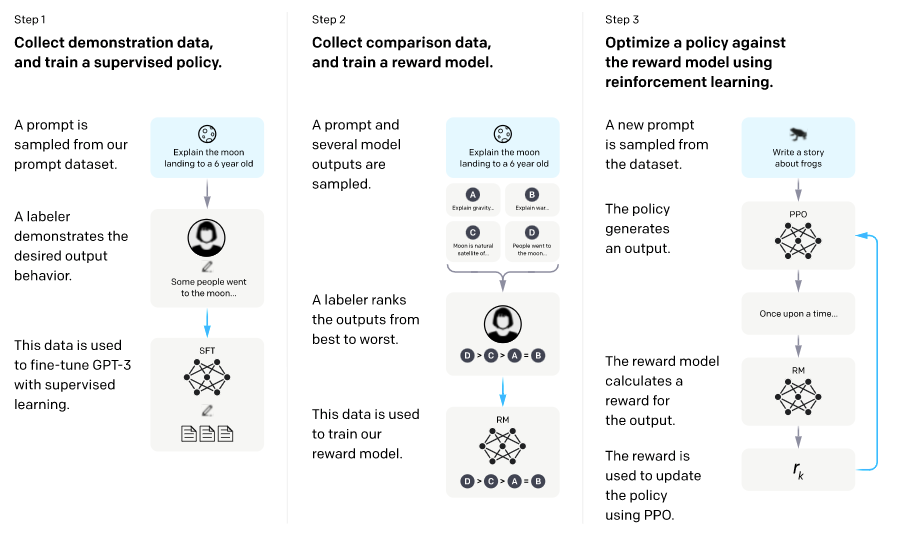
결과는?
이렇게 “빡세게” 학습 시킨 결과는 어떨까요?

해로움(Toxicity), 진실성(Truthfulness), 고객응대성(customer assistant appropriate) 등 여러 벤치마크 데이터셋을 돌려보니 이렇게 학습된 InstructGPT는 모든 방면에서 좋은 성능을 보여줍니다.
이런 테스트를 거쳤기 때문에 API의 기본 모델을 바꾸는 결정을 할 수 있었겠죠. 벤치마크 데이터 셋이 ML 시스템 개발에 얼마나 중요한지를 다시 한번 보여주는 예시인 것 같습니다.
물론 이렇게 추가 학습을 시켰어도 거대 언어 모델이 가진 여러 한계점이 전부 없어진 것은 아닙니다. 원 논문에서는 아직 풀어야 할 숙제와 방향성을 제시하는데요. 더 자세한 내용은 논문을 직접 참고하시길 바랍니다.
오늘은 OpenAI에서 어떻게 용 한마리, 아니, GPT 모델을 길들이고 있는지 알아보았습니다. 조금 방법은 다르지만 여러모로 지난 번에 다룬 LaMDA의 철학/학습 방식과도 일맥상통하는 부분이 있는 것 같습니다. 혹시 지난 글을 아직 읽어보시지 않았다면 함께 일독을 권합니다.
또한, 처음으로 강화학습(RL)이 NLP에 응용된 연구를 소개해보았습니다. 전에 댓글로 NLP+RL 연구 사례를 궁금해하셨는데, 이번에 적절한 논문이 발표되어 리뷰하였습니다. 제가 RL 전문가는 아니기 때문에 더 깊게 들어가기는 어렵지만, 혹시라도 피드백이 있다면 댓글로 부탁드리겠습니다.

Reference
- Ouyang et al., 2022, Training language models to follow instructions with human feedback
- OpenAI Blog, Aligning Language Models to Follow Instructions



