Week 54 - 생각의 흐름을 설명하는 초거대 언어 모델, 구글 PaLM


GPT-3, LaMDA 등, AI 대기업의 초거대 언어 모델 스케일 경쟁은 언제까지 계속 될까요? 이번에는 구글(Google)이 얼마 전 람다에 이어 새로운 언어 모델을 가지고 왔습니다. 무려 5400억(540B) 개의 파라미터(!)를 가진 모델을 학습 시켰고, 여러 NLP 벤치마크에서 최고 기록들을 경신하였습니다. 이렇게 스케일이 커질수록 퍼포먼스가 증가한다는 명제가 아직도 깨지지 않고 있습니다.
단순히 트랜스포머 모델을 훨씬 더 크게 만들어 많은 양의 데이터에 학습 시켰다는 것 외에 특이사항이 없다면 이 리뷰에 제가 쓸 것이 없겠죠. Pathways Language Model (PaLM)의 어떤 것을 주목해야 할까요?
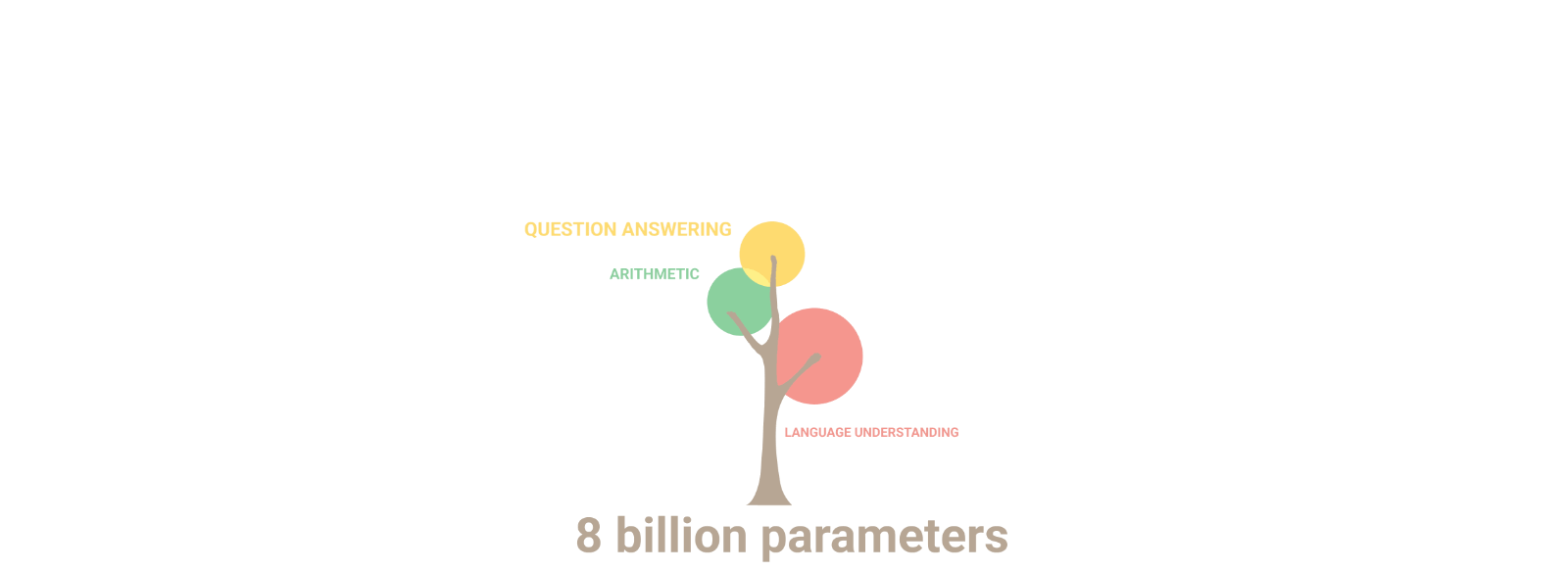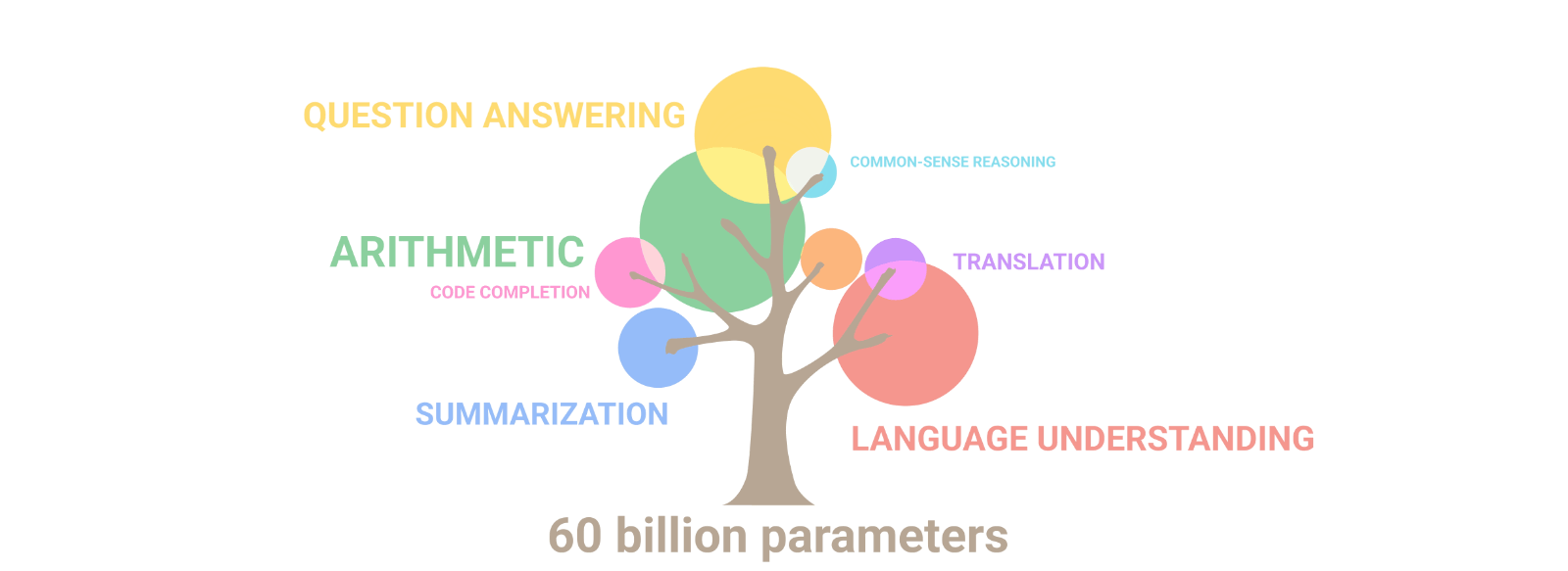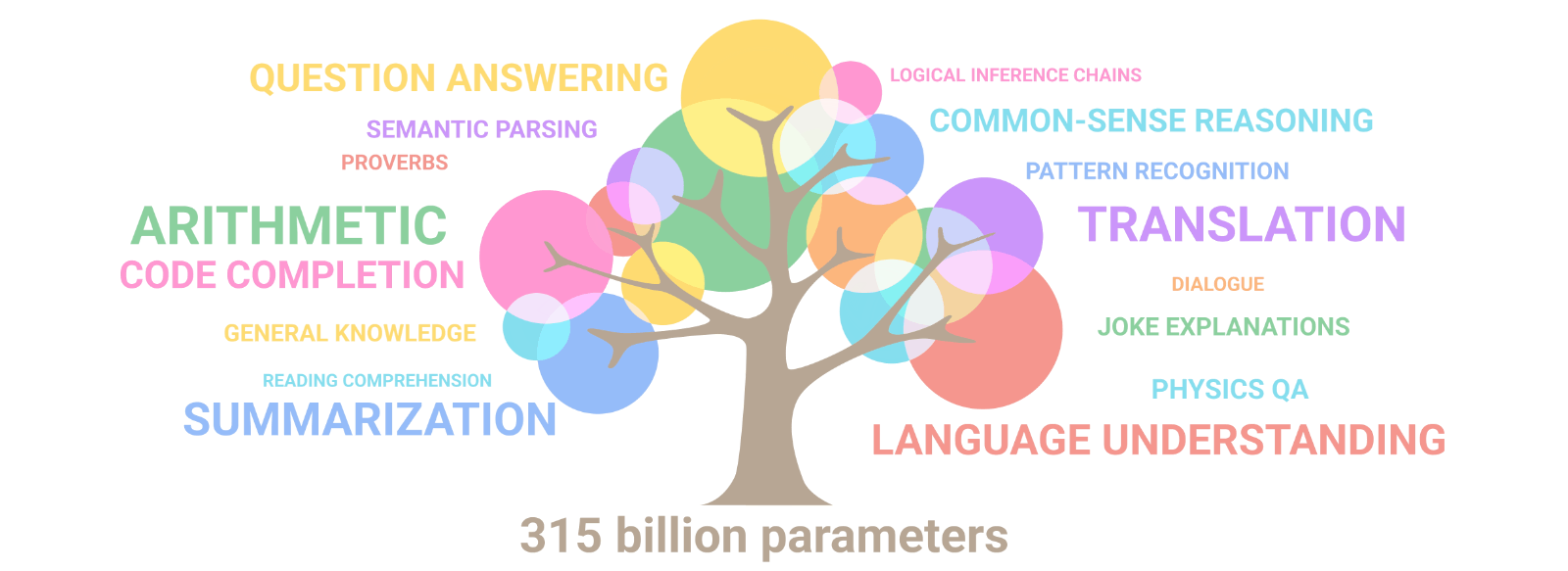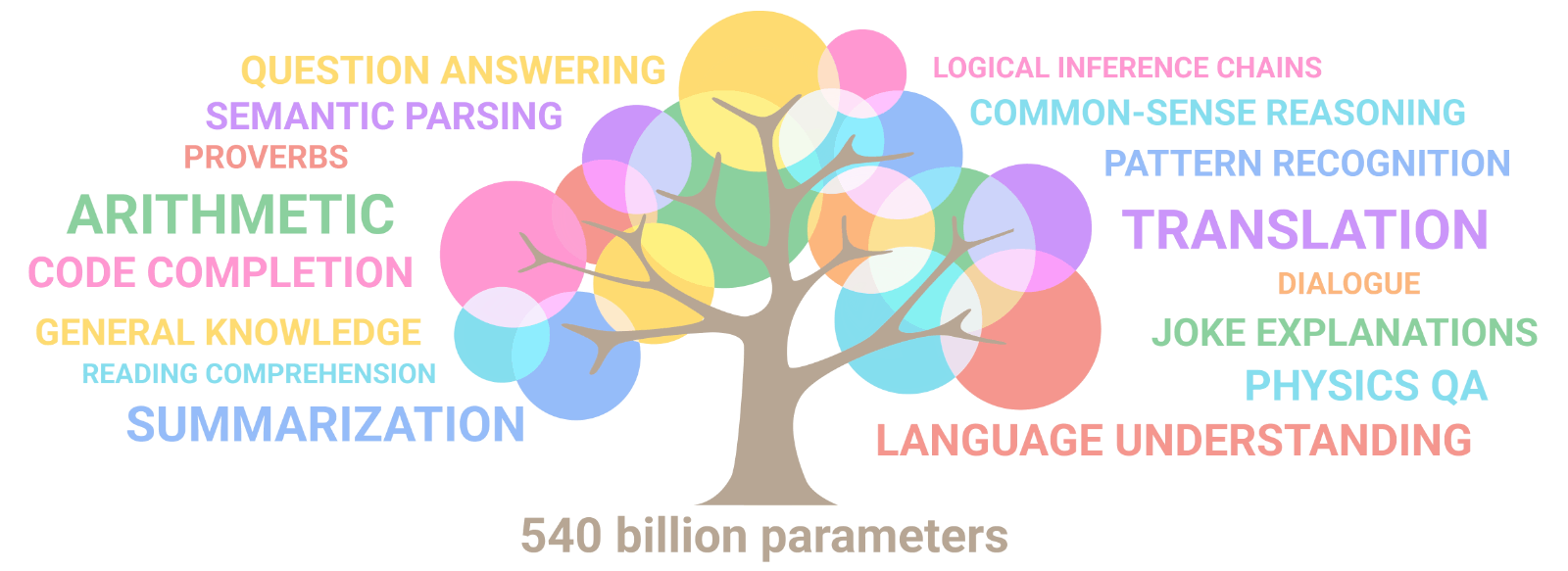
첫번째는 어떻게 이런 스케일을 이룰 수 있냐는 것입니다. 이를 위에서는 꽤나 수준 높은 병렬 처리 엔지니어링이 필요한데요. 구글에서 이 모델을 학습시킨 Pathways라는 머신러닝 워크플로우를 논문으로 공개하였습니다.
두번째는 학습 방식에 있습니다. 거대 언어 모델의 스케일을 증가시켜도 풀기 어려워 하는 문제가 추리(Reasoning) 관련 NLP 문제였습니다. 이번에 PaLM은 Chain-of-thought Prompting이라는 방식을 통해 생각의 흐름을 함께 학습시켰더니 큰 폭의 성능향상을 보였습니다.
이번 글에서는 이 두 가지 위주로 PaLM 논문을 리뷰해보도록 하겠습니다.
*이 글은 공개된 연구 논문을 바탕으로 작성되었으며, 소속된 회사의 입장이 아닌 개인의 의견임을 미리 밝힙니다.

모델 구조에 혁신이 정말 없나?
딥러닝 연구 초반에는 정말 많은 논문들이 새로운 구조를 제시하며 더 성능이 좋은 모델을 공개해왔습니다. 특히 CNN이 컴퓨터 비전 분야를 하나하나 정복해나갈때 그런 경우가 많았죠. 하지만 GPT가 공개된 후에는, NLP 언어 모델에는 큰 변화가 없었습니다.
그저 (decoder만 사용한) 트랜스포머를 사용했죠. 다만 얼마나 큰 스케일을 만들 수 있느냐가 쟁점이었습니다.
이번 PaLM 역시 마찬가지입니다. 본문이 약 50쪽짜리 되는 논문에 모델 구조(Model Architecture)는 단 한 쪽(!)에 불과합니다.
앞으로도 기초 모델(Foundational Model)에서는 “구조는 단순하게, 스케일은 크게, 데이터는 다양하게 많이”라는 경향이 계속 될 것 같습니다.
구글의 Pathway System이란?
작년 2021년 10월, 구글 리서치 조직의 수장 제프 딘(Jeff Dean)이 Pathways라는 모델 구조 컨셉을 구글 블로그를 통해 발표했었습니다. 논문이 아니라 굉장히 추상적인 글이라 많은 궁금증을 자아내었죠.
Today's AI models are typically trained to do only one thing. Pathways will enable us to train a single model to do thousands or millions of things.
(지금 AI 모델은 한 가지 문제를 위해 학습된다. Pathways는 한 가지 모델로 수천 수백만 가지의 일을 하게 될 것이다)
아마 한두 개의 연구가 아니라 구글의 AI 연구의 큰 비전을 그리기 위해 발표된 것 같고, 이에 후속작으로 이번에 PaLM 및 여러 연구 논문이 발표되었습니다.
Pathway 인프라
PaLM은 무려 6144 개의 TPU(구글의 GPU 칩)를 약 1500여 개의 호스트 컴퓨터를 통해 학습되었습니다. 이건 정말 엄청난 스케일인데요. 이번에 공개된 Pathway ML 인프라 논문에서 이 분산 컴퓨팅 시스템이 어떻게 작동되는지 공개되었습니다.
개인적으로 이 분야로는 문외한이라 자세히 설명하지는 못하겠지만, 이번 시스템을 이용함으로써 학습에 사용되는 컴퓨팅의 효율이 상당히 좋아졌다고 합니다. 특히 언어 모델 학습 효율성을 측정하기 위해 Floating Point Operations per second(FLOPs) Utilization이라는 지표를 사용하는데, GPT-3와 비교했을 때 2배 이상의 효율을 보여줍니다. 그렇기 때문에 GPT-3보다 3배 이상으로 규모가 큰 모델을 학습시킬 수 있었던거죠.
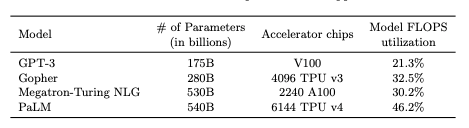
지금이나 앞으로나 머신러닝 모델의 스케일이 중요해지며, AI 기업들의 분산 컴퓨팅 인프라 역량이 매우 큰 차이를 만들어 내지 않을까 생각합니다. 이정도 스케일을 단 한 개의 워크스테이션에 담아낼 수는 (아직) 없으니까요. 이런 것을 보면 수년 간 쌓아온 구글 조직의 거대 스케일에 대한 엔지니어링/컴퓨팅 능력은 굉장한 강점으로 나타나는 것 같습니다.
PaLM의 성능
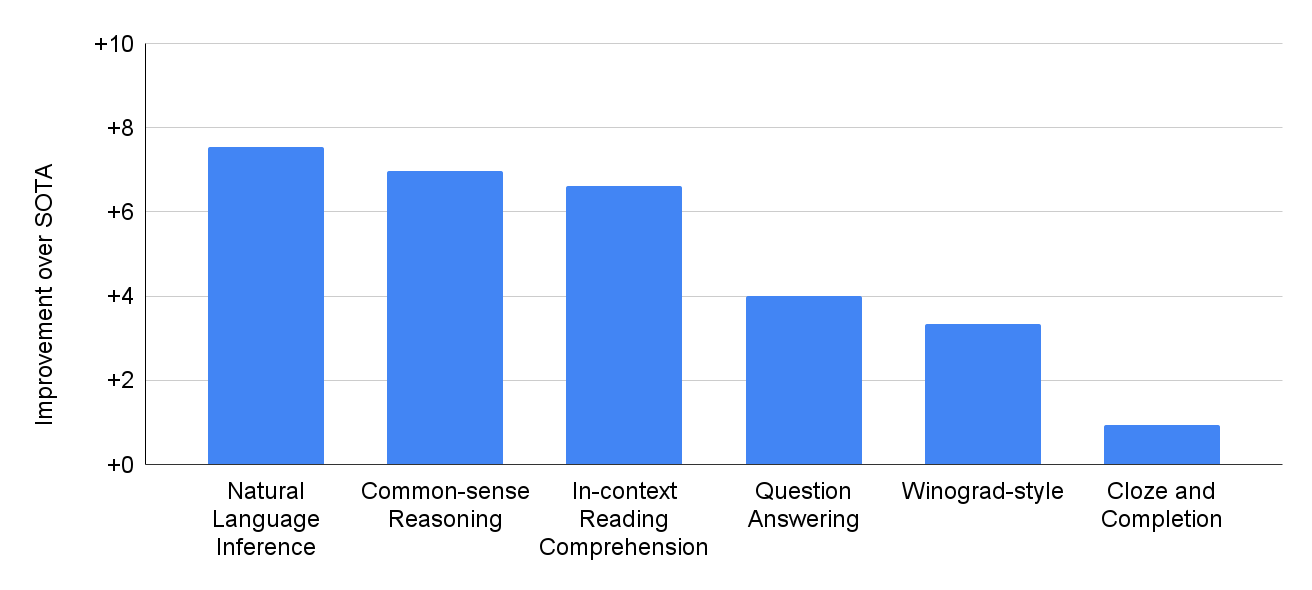
PaLM은 약 30 여개의 다양한 NLP 벤치마크 데이터 셋에서 GPT-3, LaMDA를 비롯한 기존 모델보다 더 나은 성능을 보여줍니다. 여기서 하나하나 다 설명을 하면 너무 길어지지만, 재밌는 점은 학습 데이터에 비영어 데이터가 22% 밖에 안되지만, 영어 뿐만 아니라 다국어 문제에서도 좋은 성능을 보여주었다는 점과, 깃허브(Github) 데이터도 포함이 되어 프로그래밍 코드 작성 문제도 풀 수 있다는 점입니다.
(Copilot 등 코드 생성 관련 논문은 나중에 따로 리뷰해보도록 하겠습니다.)

생각에 생각이 꼬리를 무는 Chain-of-thought prompting
중고등학교 때 서술형 수학 문제를 풀 때가 기억나시나요? 아무리 간단한 문제라도 중간 과정을 설명하지 않고 답만 적어내면 맞았어도 감점을 받고는 했었죠. 단순히 선생님의 채점을 쉽게 하려고 한 것도 있지만, 학생이 제대로 답을 찾아 나가는 과정을 이해를 하고 있는 것인지 확인하기 위함입니다.
이러한 방식을 언어 모델에게도 적용해보면 어떨까요? 바로 이를 Chain-of-thought prompting이라고 부릅니다.

위 예시를 보면 최종 답에 대한 중간 과정에 대한 설명(노란색)이 들어간 것을 볼 수 있습니다. PaLM을 학습할 때 추리(Reasoning) 관련 기존 데이터셋을 확장시켜 이런 식으로 중간 논리를 설명한 부분을 넣었더니, 성능이 확연히 올라갔다고 합니다!
아무래도 중간 과정 설명이 답을 추론하는데 더 많은 정보와 연결고리를 주는듯 합니다. 정말 인간이 추론을 하는 것과 매우 닮아가는 것 같네요! 예시를 몇개 더 볼까요.
Chain-of-thought prompting은 단순히 성능 증가 뿐만 아니라 언어 모델이 어떻게 답변에 도달하는지 인간이 이해할 수 있는 언어로 설명하기 때문에 모델의 투명성/설명성 증가에도 중요한 연구인 것 같습니다.
Week 39: AI로 팔 수 없는 것들에서 AI 시스템의 예측 및 실수를 설명하기 힘들다는 것이 실전 적용에 큰 단점이 될 것이라고 지적하였는데, 어쩌면 이를 극복하기 위해 앞으로 이러한 기법이 계속 사용되지 않을까 싶습니다.
*구글 리서치 팀에서 PaLM 본 논문 외에 따로 Chain-of-thought prompting에 대해 논문을 공개하였으니 참고하시길 바랍니다.
오늘은 구글의 PaLM 거대 언어 모델을 리뷰해보았습니다. 정말 하루하루 거대해지는 스케일, 언제까지 계속 갈까요? 앞으로 이러한 기초 모델들이 실생활에 어떻게 활용될 수 있을까요? 이러한 기초 모델 연구도 흥미롭지만, 응용이 더더욱 기대되는 것 같습니다.

Reference
- Chowdhery et al., 2022, PaLM: Scaling Language Modeling with Pathways
- Wei et al., 2022, Chain of Thought Prompting Elicits Reasoning in Large Language Models
- https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
- https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html



