Week 32 - AI 챗봇이랑 윤리랑 무슨 상관인데? <개인정보 편>


누구나 심심하거나 외로울 때 대화를 해줄 수 있는 AI. 영화 <Her>의 사만다를 떠올리게 하는 제품 이루다 는 2021년 우리에게 AI에 대해 새로운 방향으로 생각해 볼 계기가 되었다고 생각합니다. 결국에는 여러 논란으로 인해 이루다는 서비스가 중단 되었습니다만, 이 논란이 남긴 여러 문제는 한번 짚고 넘어가야 할 가치가 있습니다.
지난 글 에서는 이루다 같은 자유 주제 대화형 챗봇의 기술적인 부분에 집중했다면, 이번에는 윤리적인 부분에 집중해보겠습니다. '윤리' 같은 단어는 학창 시절 듣던 과목 이름 이외에 드물게 사용되는 단어죠. 도대체 AI 챗봇이랑 윤리랑 무슨 상관일까요?
윤리[倫理]
* 사람으로서 마땅히 행하거나 지켜야 할 도리.* (철학) 인간 행위의 규범에 관하여 연구하는 학문. 도덕의 본질ㆍ기원ㆍ발달, 선악의 기준 및 인간 생활과의 관계 따위를 다룬다.
이번 글에서는 먼저 AI 윤리 중 우리에게 가장 직접적이고 밀접한 관계를 가진 개인 정보에 대하여 이야기해보겠습니다.

개인 정보가 담긴 데이터 수집하긴 했는데..
개인 정보가 담긴 데이터를 사용하는 것은 많은 회사들에게 양날의 검입니다. 데이터가 많아서 학습된 모델이 큰 경쟁력을 가질 수 있지만, 조심하지 않아 유출이라도 된다면 특정 사용자에게 엄청나게 큰 피해를 입힐 수 있다는 것을 명심해야 합니다. 특히 이름, 주소, 계좌번호, 전화번호 같은 개인식별정보(Personal Identifiable Information; PII)라면 더더욱 그렇겠죠.
그렇기 때문에 데이터를 수집한 이후에도 PII가 들어간 부분은 내부 직원이라도 누군가가 보기도 전에 가리는 것이 가장 좋겠지만, 문제는 누가 보기도 전에 어떻게 PII인지 알고 가리거나 삭제를 하냐는겁니다. 텍스트를 읽지도 않고 어디서 어디까지가 개인정보인지 인지하는 그런 초능력이 있는 사람은 없을테니깐요.
그렇기 때문에 역시 자동화된 컴퓨터가 역할을 해야 합니다. 데이터를 수집한 후 자동으로 개인정보를 삭제하거나 가리고 나서 DB에 저장한다면 어떨까요? 이러한 작업을 개인식별정보 삭제(PII redaction)이라고 부릅니다. 이러한 작업은 AI 모델이 할 수도 있고, 여러 가지 수동 규칙으로 할 수도 있습니다. 개인정보가 많이 있는 데이터를 많이 다루는 회사라면 이러한 모듈을 꼭 자체 개발하거나 이미 있는 솔루션을 이용해야 한다고 생각합니다. 예를 들어 AWS에서는 개인정보 제거 API를 제공하고 있습니다.

스캐터랩의 블로그에 의하면 이러한 필터링 작업을 하였으나 완벽하지 않았다는 점을 사과문을 통해 인정하였습니다. 완벽하지 않은 상태에서 제품을 공개한 것은 윤리적으로 비판 받아 마땅하지만, 실제로 정말 어려운 문제이기도 합니다. 아래와 같은 경우를 볼까요.

숫자를 한글로 쓴다거나 작은 오타가 있는 경우, 사람 눈에는 무척 간단해보이지만 잘 설계하지 않으면 이러한 작은 부분을 놓치기 쉽습니다. 위의 예시는 매우 뻔하지만 이 외에 제가 생각하지 못하는 꽤 까다로운 경우도 많을 것이라고 생각합니다.
그렇기 때문에 개인식별정보 삭제 모듈은 precision 보단 recall에 조금 더 무게를 더 좋지 않을까 싶습니다. 개인정보가 아닌 부분까지 삭제하는 실수를 범할 수도 있지만, 개인정보가 데이터에 남아있을 확률을 최대한 줄이는게 중요하니깐요. (Precision, Recall의 개념 잡으려면 이 블로그를 참고)
이러한 작업을 제대로 하지 않으면 모델이 학습 데이터에 남아있는 개인정보를 유출할 가능성이 높아집니다. 이는 지난 주에 설명한 두 가지 종류의 챗봇, 1. 답변 생성형 챗봇 (Generative Converational Model), 2. DB에서 답변을 고르는 모델 (Retrieval-based model) 모두 해당됩니다.
이번에 논란이 된 이루다는 2번째 방식을 기반으로 하고 있기 때문에 개인정보가 어떻게 유출될 수 있는지 직관적으로 이해가 됩니다. 사용자의 답변이 토씨 하나 틀리지 않고 그대로 답변 후보 DB에 저장이 될 수도 있기 때문이죠. 하지만 GPT-3 같은 언어 모델을 기반으로 답변을 생성하는 모델도 개인정보를 유출할 수 있다니요? 언어 모델은 학습 데이터에서 단어 간의 패턴을 뽑아내고 이를 모델 파라미터(parameter)로 저장하는게 아니었던가요? 직접 본 텍스트를 기억하고 저장하는게 아니지 않나요..?
거대한 언어모델도 개인정보 유출이 가능하다
네, 맞습니다. 하지만 그렇다고 개인정보가 완전히 보호 되는 것이 아니라고 최근 구글, OpenAI, 애플, 스탠포드, 버클리, 노스이스턴 대학 연구자들의 합동 연구를 통해서 밝혀졌습니다.
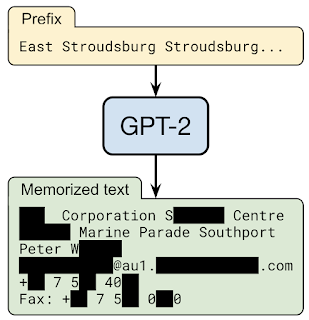
GPT-2를 학습시키고 여러 가지 샘플링 전략으로 텍스트를 생성하게 하고, 미리 선별해놓은 1800 개의 텍스트 중 몇 개가 그대로 생성되는지 확인해보았습니다. 1800 개 중에는 기사 헤드라인, Javascript 코드, 개인정보(이름, 주소 등 PII)가 포함된 텍스트가 포함되어있는데, 약 600개 이상의 텍스트가 토씨도 틀리지 않고 그대로 생성되어 노출되는 것을 확인하였습니다.
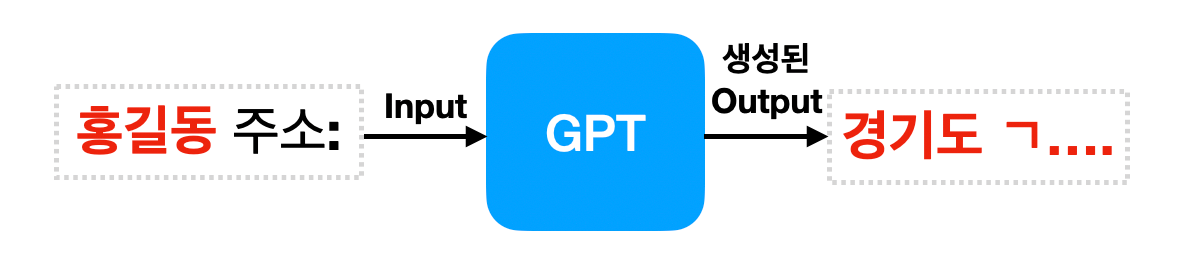
더욱 놀라운 것은 학습 데이터에 단 한번 나타난 텍스트도 모델이 외우고 있었다는 겁니다. 예를 들어, "홍길동의 주소는 서울시 종로구 익선동이야"라는 문장이 방대한 인터넷 학습 데이터에 단 한번 등장했음에도 불구하고 언어 모델이 그대로 문장을 재현해냈다는 것 입니다.
이러한 경향은 더 큰 모델일수록 더 커졌습니다. 1.5B 파라미터를 가진 GPT-2 XL모델이 124M 파라미터를 가진 GPT-2 Small모델 보다 약 10배 정도 학습 데이터를 외우는 경향을 가지는 것으로 파악되었습니다. 그렇다면 훨~씬 더 큰 GPT-3 같은 모델은 더더욱 이 문제에 취약하다는 것이죠. (GPT-2와 3의 차이를 공부하려면 Week 29를 참고) 아무래도 모델의 크기가 커지면서, 저장할 수 있는 양의 정보도 기하급수적으로 커지기 때문에 이러한 현상이 일어나는 것 같습니다. 일종의 오버피팅이라고 해야할까요.
이는 공개된 언어 모델을 악의적인 의도를 가지고 사용한다면 충분히 기존 데이터를 훔쳐내거나 그 안에 들어있는 개인정보를 뽑아낼 수 있다는 의미입니다. 인터넷에 어쩌다 한번 노출된 나의 정보가 아주 손쉽게...
이 연구는 인터넷 데이터로 학습된 거대한 언어 모델을 아무런 조치 없이 그대로 공개해버리는 것은 윤리적인 문제가 발생할 수 있다는 점을 제대로 꼬집고 있습니다. (사실 GPT-3를 유료로 API화하려는 OpenAI에서 이러한 연구를 함께 한 것도 흥미롭네요.)
단순히 지우는거 말고 할 수 있는 거 없나?
많은 기업들이 개인 유저들이 생성해낸 데이터를 활용해 더 많은 ML 모델들을 학습하려고 하지만, 앞서 말한 개인정보 관련 윤리 문제가 발목을 잡습니다. 그리고 단순히 데이터에서 PII를 지워버리는 것이 쉽지도 않고 충분하지 않을 수도 있습니다. 그래서 이 방향으로 굉장히 많은 연구와 개발이 진행되었는데, 그 중 대표적인 것이 바로 Differential Privacy와 Federated Learning입니다.
Differential Privacy
Differential Privacy는 데이터에 어떠한 일정한 통계학적 소음(noise)를 주입하여 모델이 어느 하나의 데이터 포인트의 개인을 특정할 수 없게 하는 방법입니다. 애플을 비롯한 많은 기업에서 이미 사용하고 있는 방식입니다.
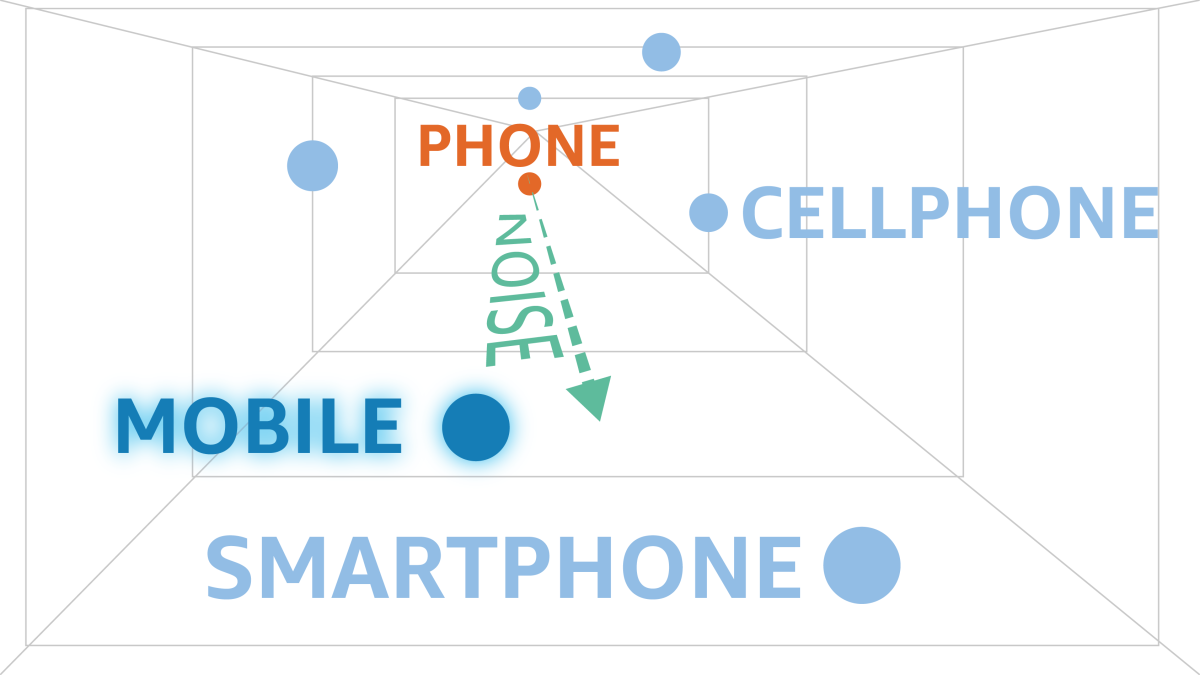
하지만 텍스트는 숫자가 아닌데 어떻게 소음을 주입할 수 있을까요? 이는 바로 텍스트를 숫자로 변환한 vector space(ex. word embedding, sentence embedding)에서 소음을 주입하는 것 입니다.
예를 들어, 아마존에서 발표한 연구에 따르면 우리가 배운 word embedding에 잘 설계된 노이즈를 주입하면 유저의 텍스트 데이터와 GPS 위치 데이터를 함께 학습할 때 GPS 같은 민감한 정보가 노출되지 않게 된다고 합니다.
Federated Learning
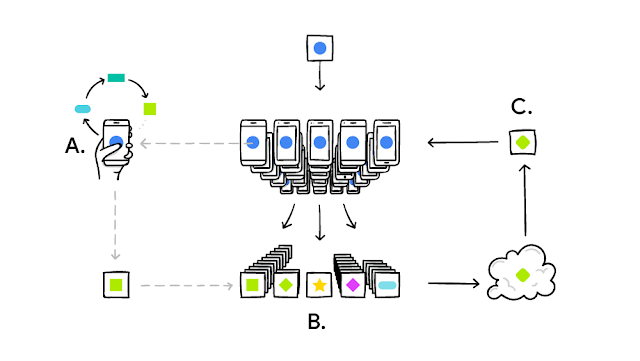
Federated Learning은 한글로 하면 연합 학습이라고도 하며, 한 기계에서 머신러닝 모델을 학습시키는 것이 아니라 여러 분산된 기계에서 연합으로 학습시키는 방법입니다. 이를 활용한 대표적인 예가 바로 구글의 Gboard의 자동완성 기능입니다.
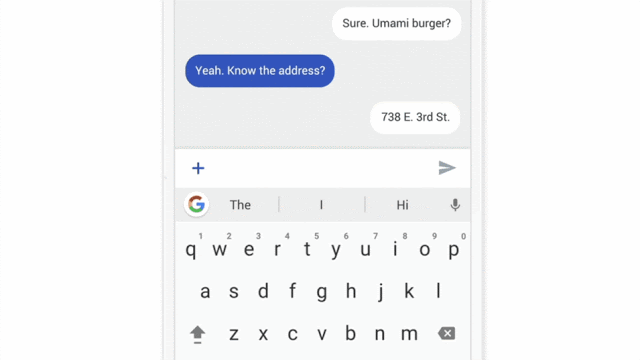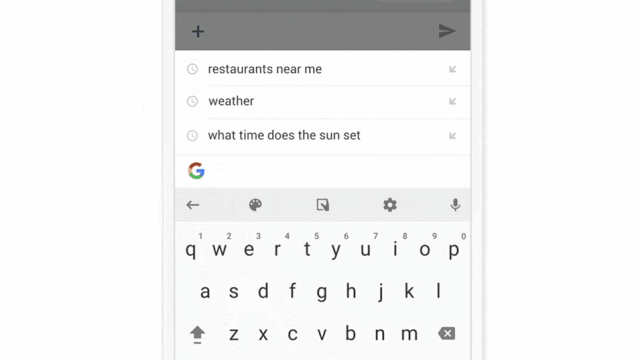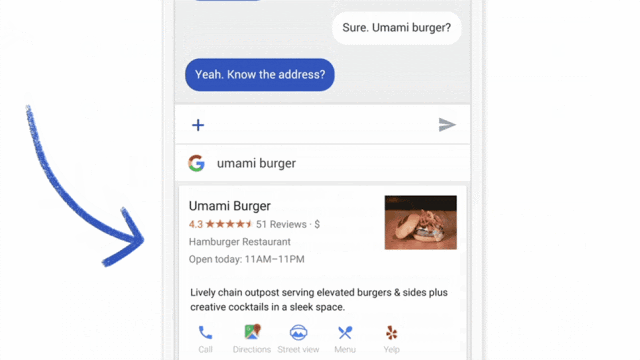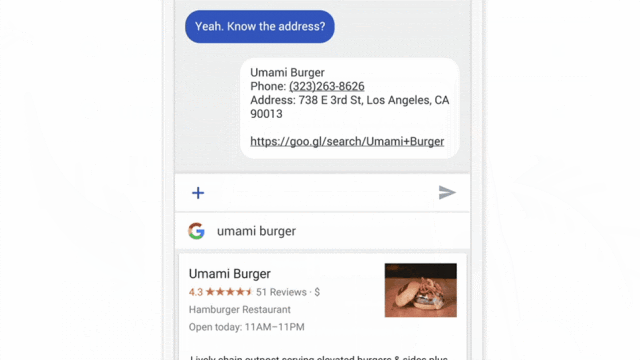
키보드에서 생성된 유저의 데이터를 클라우드 같은 중앙 시스템이 올릴 필요 없이 각 스마트폰 자체에서 기존 모델을 개선시키는데 사용합니다. 그리고 개선된 부분 중 필요한 부분만 클라우드로 업로드됩니다. 여기서 필요한 부분은 텍스트 데이터가 아니라 이미 계산이 끝난 숫자로 구성되기 때문에 어떤 데이터도 유출되지 않습니다.
게다가 개선된 모델은 본인의 데이터를 사용했기 때문에 그대로 개인화된 경험을 누릴 수 있습니다. 안드로이드 폰에서 자동완성을 쓰다보면 더더욱 나의 다음 단어를 잘 예측한다고 느끼신적이 있으신가요? 바로 GBoard의 이러한 기술을 이용한 덕분입니다.
이처럼 수집한 개인 정보를 잘 처리하지 못하고 무분별하게 NLP 모델에 사용하면 어떠한 문제가 발생할 수 있는지 알아보았습니다. 개인정보 유출은 실질적으로 누구에게 피해를 입힐 수 있기 때문에, 이를 심각하게 여기고 신중하게 여러 조치를 하지 않은 것은 비윤리적인 것이라고 할 수 있겠습니다. 물론 어떤 기술이든 완벽할 순 없기에 문제점이 나타날 수 있지만, 이를 어떻게 대응하는지도 중요한 문제겠지요.
뒤에는 애플, 구글, 아마존 같은 NLP와 ML을 선도하는 기업들이 이 문제를 해결하기 위해 쓰이는 대표적인 기술 2가지를 소개해보았습니다. 개인 정보 유출이 심각한 문제라고 인식하고 이를 기술적으로 해결하려는 여러 연구자, 개발자들에게 큰 존경을 표합니다.
다음 글에서는 AI챗봇이 가질 수 있는 다른 윤리 문제인 팩트 체크와 편견/혐오 발언 문제를 다뤄보려고 합니다.

Reference
- Carlini et al., 2o20, Privacy Considerations in Large Language Models, Google AI Blog
- Carlini et al., 2020, Extracting Training Data from Large Language Models, 논문
- Diete, 2020, Preserving privacy in analyses of textual data, Amazon Science
- McMahan et al., 2017, Federated Learning: Collaborative Machine Learning without Centralized Training Data, Google AI Blog



