Week 45 - 한국어 최강 언어모델 등장! HYPERCLOVA 리뷰


GPT-3의 공개가 세상을 놀래킨지 1년 정도의 시간이 지났습니다. 엄청난 모델 스케일 뿐만 아니라, 이 모델을 이용한 다양한 응용 케이스들이 많은 관심을 끌고 있습니다. 그만큼 NLP라는 분야에 큰 획을 긋고 있고, 앞으로의 발전이 더 기대되는 연구가 바로 GPT입니다.
그런데 지금까지 공개된 GPT의 단점은 영어 중심이라는 것입니다. 인터넷에서 텍스트를 크롤링해서 얻는 방식으로 학습 데이터를 구축했기에, 그리고 가장 널리 보편적으로 쓰이는 언어가 영어이기 때문이지만, 한국에서 NLP 기술을 사용하고 싶은 분들에게는 아쉬움이 있으셨을꺼라 생각이 듭니다.
2021년, 드디어 한국어 기반의 GPT-3 모델이 등장하였습니다! 바로 네이버의 AI 연구자/엔지니어 분들이 만든 하이퍼클로바(HyperCLOVA)입니다. 이번 글에서는 9월 하이퍼 클로바의 논문을 통해 공개된 연구를 살펴보겠습니다. 특히 어떻게 GPT-3가 한국어 기반이 될 수 있는지, 그리고 연구자 분들이 그리는 NoCode AI 개발에 대한 비전을 이야기해보겠습니다.
*이 블로그는 제가 소속된 회사의 입장이 아닌 개인 의견임을 밝히며, 이 글에 나오는 연구 주체인 네이버와도 교감 없이 논문에 공개된 내용을 기반으로만 작성된 글입니다.

HYPERCLOVA의 스케일
GPT-3의 스케일이 공개되었을 때는 이에 대한 많은 논란이 있었습니다. "이렇게 큰 모델이 필요한가..", "이제는 돈 없으면 AI를 못하는 시대인가..", "컴퓨팅 파워를 너무 낭비하는 환경 파괴의 주범이 아닌가.." 등등.
한국어라고 하더라도 모델의 스케일이 무척 커야 GPT-3 원 논문에서 보여준 성능을 보여줄 수 있기 때문에, 어느 개인이나 공공 연구소에서 하기는 쉽지 않은 프로젝트였습니다. 가장 먼저 비용이라는 한계가 있을 것이고, 그리고는 스케일을 다룰 수 있는 엔지니어링 능력이 필요합니다.
이렇게 큰 모델을 학습 시키려면 아직까지는 단 한 대의 컴퓨터로 가능하지 않습니다. 여러 대의 서버로 분산을 시켜 학습하고, 결과를 합산시켜야 모아야 하지요. 아무리 머신러닝 관련 분산 컴퓨팅에 대한 여러 연구나 오픈소스 솔루션이 나와있다고는 하지만 GPT-3 규모의 모델을 학습 시키려면 아주 높은 엔지니어링 인프라가 필요합니다.
HYPERCLOVA 역시 128 대의 서버에서 총 1024 개의 GPU를 이용하여 학습되었다고 합니다. 820억(82B)의 파라미터를 가진 모델 한개를 학습시키는데만 약 13.4일이 걸린다고 하는데요. 이를 돌리는데 드는 비용은 공개되지는 않았지만 꽤나 어마어마할 것 같습니다.
그럼에도 불구하고, OpenAI에서 공개한 모델 중 가장 큰 규모인 1750억 파라미터 모델보다는 작습니다. 너무 큰 모델은 학습 비용도 많이 들고, 활용할 때 역시 비용과 속도 면에서 제약이 있을 수 있기에, 좀 더 활용도가 높은 미들급의 모델을 지향했다고 합니다.
하이퍼클로바의 학습 데이터
이렇게 큰 언어 모델은 역시 학습 데이터가 중요합니다. 네이버는 꽤 오랜 기간 다양한 IT 서비스를 운영해왔기에 한국어 데이터를 가장 많이 보유하고 있는 회사 중 하나라고 해도 과언이 아닐 것 입니다. 어떤 종류의 데이터가 이용되었는지 한번 살펴볼까요.
- 네이버 블로그
- 네이버 카페 커뮤니티 글
- 네이버 뉴스 기사 본문
- 네이버 뉴스 댓글
- 네이버 지식IN Q&A
- 국립 국어원 모두의 말뭉치 일부분
- 위키피디아 (영어/일본어)
어떻게 보면 가용할 수 있는 텍스트 데이터를 다 끌어와 집어 넣었다고 볼 수 있겠는데요. 오늘까지 수 년간 데이터를 차곡차곡 모아온게 빛을 발하는 순간인 것 같습니다.

데이터는 법적으로 사용에 문제가 없는 것들로만 추렸고, 혹시라도 등장하는 개인 식별 정도(PII)는 거를 수 있도록 처리를 하였다고 합니다. 이전에 이루다 이슈에서 큰 문제가 되었기에 중요한 문제라고 생각되는데요. 특히 대형 언어 모델이 학습 데이터에 나오는 민감한 텍스트를 암기하는 문제가 지적되어온 만큼 HYPERCLOVA도 후속 연구가 진행되면 좋지 않을까 생각해봅니다.

한국어 토크나이제이션(TOKENIZATION)
하이퍼클로바를 학습하는데 여러 가지 세부 기법들이 사용되었습니다. Prompt Optimization이라든지, Learning rate scheduling, AdamW optimiser 등등.
하지만 중요하고 NLP에 관련된 기법 하나만 소개하겠습니다.
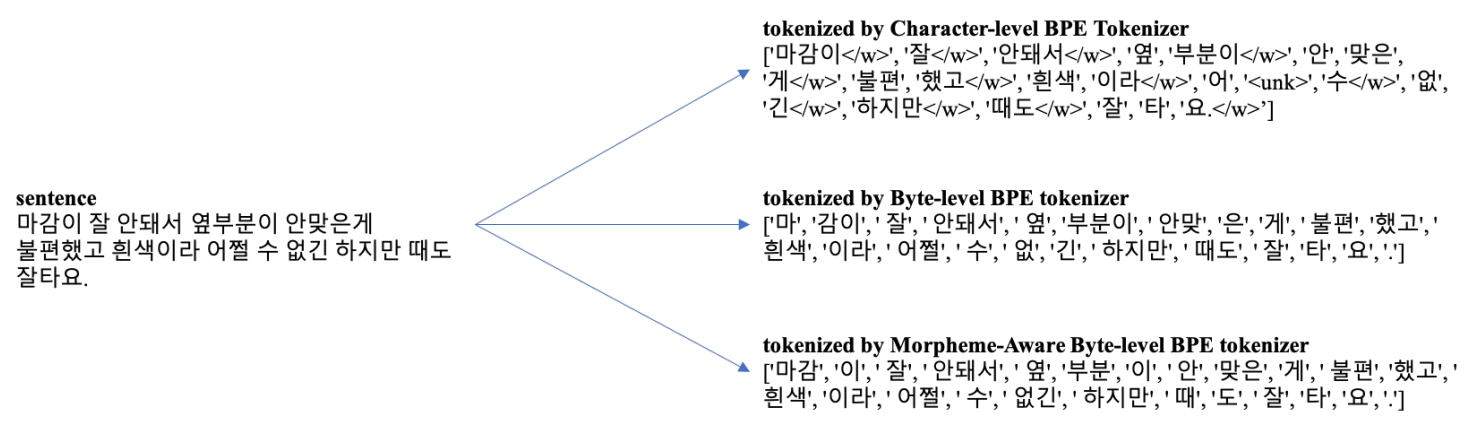
토크나이제이션은 말그대로 어떻게 텍스트를 학습 가능한 토큰으로 나누느냐의 문제입니다. 이게 왜 중요하냐면 NLP 모델은 단순히 띄어쓰기를 기반으로 텍스트를 보지 않아도 되기 때문입니다. 우리 역시 그렇죠 (인간이띄어쓰기없어도잘읽을수있는이유).
게다가 NLP 모델은 주어진 단어 또는 토큰을 숫자로 치환하여 계산합니다. 그렇기 때문에 텍스트를 어떻게 토큰으로 나누고, 각각 어떻게 숫자로 배정할 것이 매우 중요한 문제입니다.

BERT나 GPT-3 같은 경우에는 Byte Pair Encoding (BPE)라는 알고리즘을 사용하여 효율적인 토큰 나눔 방식을 찾아냅니다. 하지만 이 방식은 한국어 발음 체계를 고려하지 않아 "ㅎ", "하", "한"이 전부 다른 Byte로 인식된다는 문제가 있었습니다. 그래서 뜻을 갖는 가장 작은 단위인 형태소(morpheme)을 기반으로 토큰을 나누도록 하였고, 훨씬 더 일관적이고 효율적으로 데이터를 처리할 수 있었습니다.
이는 모델 학습에 있어서도 형태소간 파라미터 공유를 가능케하여 더 적은 파라미터로도 좋은 성능을 낼 수 있게 합니다. 논문에 이에 대한 효과를 분석한 부분이 따로 있으니 관심 있으면 Section 4.4를 보시길 바랍니다.
이렇게 하이퍼클로바를 학습하는데에는 총 5618억 개의 토큰이 이용되었습니다.
HYPERCLOVA의 문제 해결 능력
이렇게 학습된 언어 모델은 어떻게 쓰일 수 있을까요? GPT-3가 NLP 연구에 중요한 방향을 제시한 것은 단순히 스케일이 아니라 Few-shot learning이라는 문제 해결 방식이라고 배웠습니다. 따로 추가 학습 없이도 질문을 던지는 것 같은 방식으로도 답을 찾아낼 수 있는 것이 큰 장점입니다.

하이퍼클로바 역시 같은 방식으로 여러 가지 문제에 대해 성능 측정을 하였습니다.
- 네이버 영화 리뷰 평점 예측 (NSMC)
- KorQuAD 1.0 (독해)
- 번역 (AI Hub 한국어-영어)
- 뉴스 토픽 분류 (YNAT in KLUE)
- 문장 유사도(KLUE STS)
- 대화 시스템 유저 쿼리 변형
비교 베이스라인으로는 한국어/다국어 BERT와 트랜스포머 기반 번역 모델을 사용하였습니다. 참고로 여기서 베이스라인 모델들은 few-shot learning이 아니라, 각 문제를 위해 추가 학습을 한 모델이라는 점이 중요합니다. 그렇기 때문에 하이퍼클로바의 성능이 베이스라인과 비슷하기만 해도 큰 성과라고 할 수 있습니다.
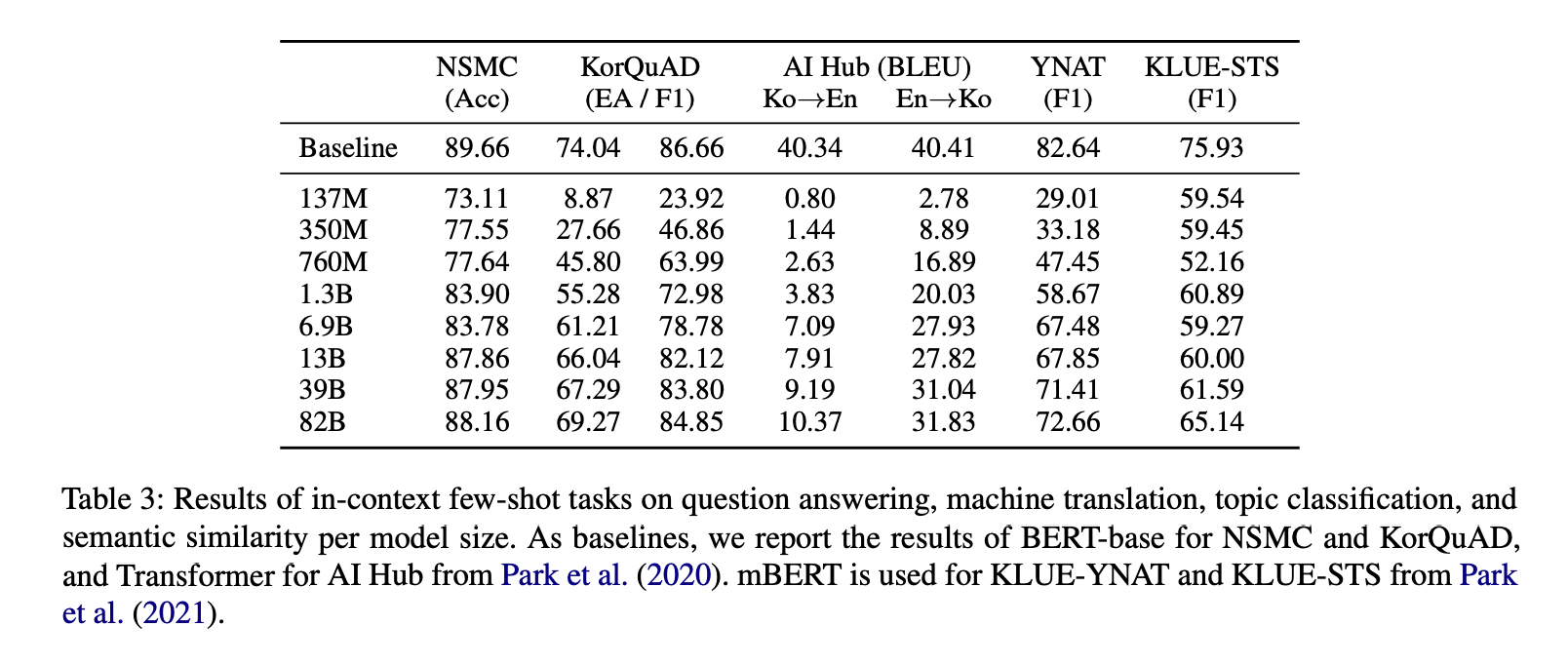
그리고 모델 파라미터 수가 성능에 어떤 영향을 끼치는지 분석하기 위해 여러 크기의 모델을 학습하여 비교하였습니다. 모델 크기가 증가하면서 성능 역시 함께 올라가는 경향을 볼 수 있습니다.
결과를 보면 대부분의 문제 종류에서 꽤나 좋은 성능을 보여준다는 것을 알 수 있습니다. 다만 번역 문제에서 가장 성능이 좋지 않은데, 아무래도 학습 데이터에 영어 데이터 또는 영어/한국어 쌍 데이터 너무 적기 때문에 그런 것이 아닐까라고 합니다.
하이버클로바는 앞으로 어떻게 쓰일까?
이 논문의 제목은:
"What Changes Can Large-scale Language Models Bring?" (대형 언어 모델은 어떤 변화를 불러올까?)
입니다. 이처럼 이 연구의 핵심은 언어 모델 자체가 아니라 어떻게 쓸 것인가에 대한 것이라는거죠. 두 가지 방향을 제시되었습니다.
NoCode AI Platform
하이퍼클로바 스튜디오(HyperClova Studio)라는 코딩 없이 AI 모델을 만드는 플랫폼을 공개하였습니다. AI 연구자나 개발자가 아닌 그냥 제품 매니저가 GUI 인터페이스를 통해 언어 모델에게 예시를 주는 등의 인터렉션을 통해 AI 모델을 개발할 수 있게 하는 도구라고 합니다.
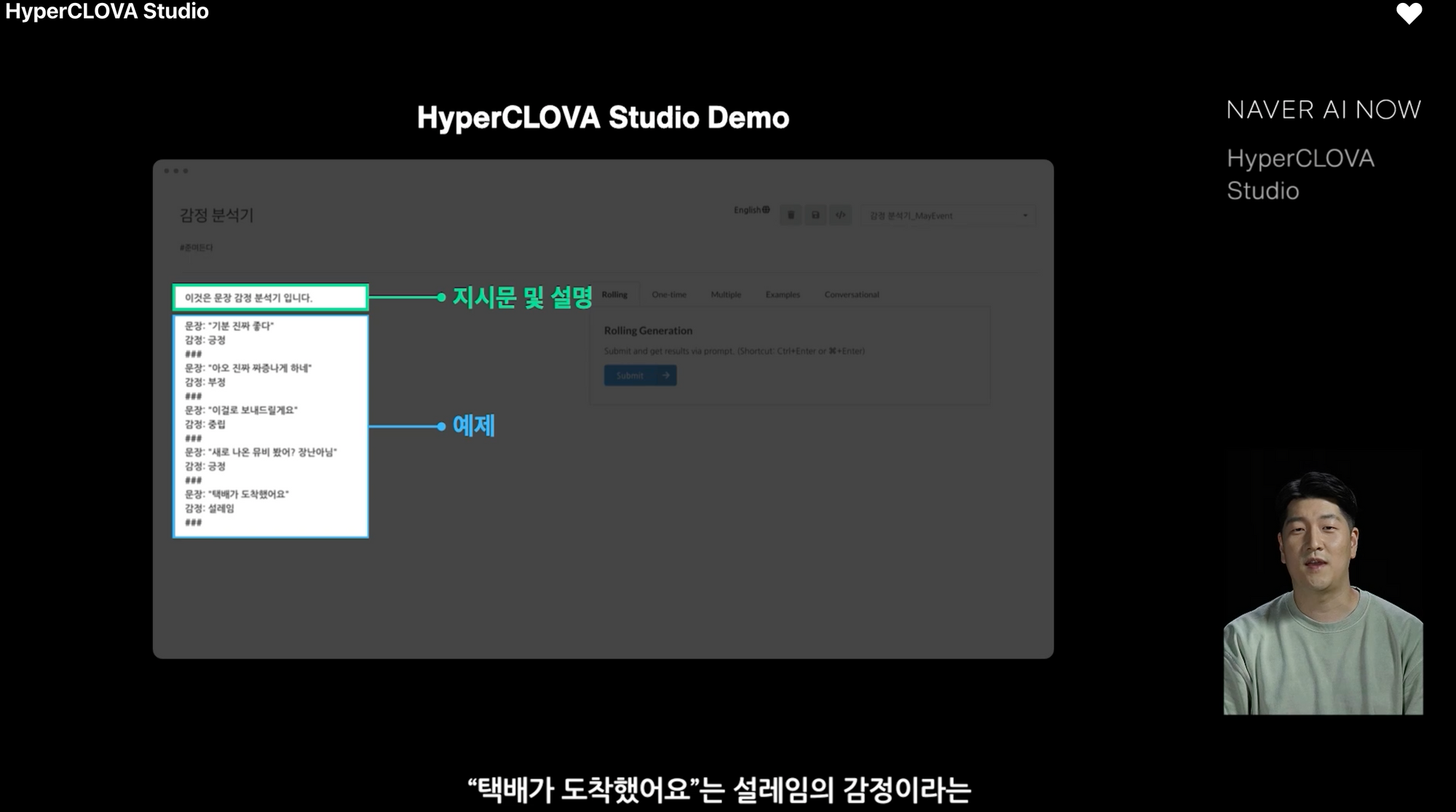
논문에서 소개한 케이스 스터디는 특정한 성격(personality)를 가진 챗봇, 이벤트 제목 생성, 대화 시스템 데이터 합성 등이 있습니다. 특히 인상 깊었던 것은 이벤트 제목 생성이었는데요. 제품 디자이너가 10분도 안 걸려 만든 예시를 인풋으로 받은 하이퍼클로바의 성능이 실제 사람이 작성한 것 못지 않은 성능을 보입니다.
이처럼 이러한 노코드 AI 플랫폼은 앞으로 더 많은 곳에 NLP 같은 기술이 쓰일 수 있도록 하는 큰 촉매제가 되지 않을까 싶습니다. 프로그래밍 역시 직접 코드를 쓰지 않고 좀 더 간단한 방식을 통해 자동화를 하는 식의 도구가 점점 더 많아지는 추세인데요. AI도 역시 그렇게 갈 수 있을까요?
가공 데이터 생성(Synthetic Data Augmentation)
하이퍼클로바의 또다른 용도는 바로 가공 데이터 생성입니다. 데이터 어그멘테이션(Data augmentation)이라고도 불리는 이 기술은 엄청나게 많은 데이터를 필요로 하는 딥러닝 모델들에게 무척 중요한 기술입니다. 데이터 수집하는데 드는 시간과 비용이 무척 비싼 것에 비해, 딥러닝 모델은 데이터가 적으면 잘 작동하지 않은 경우가 많은데요. 그래서 전에 배웠던 전이 학습(transfer learning) 같은 방식이 많이 쓰입니다.

특히 NLP 데이터 같은 경우에는 같은 의미를 가진 텍스트라도 여러 개의 형태, 방식으로 표현된 데이터가 많으면 많을수록 말을 잘 알아 듣습니다. 예를 들어, 한국어에서 간단하게 안부인사만 해도 얼마나 많은 방식이 있습니까.. (잘 지냈니? 잘 지내셨어요? 요즘 어떻게 보내고 계세요? 요즘 어때? 등등..)
그렇기 때문에 새로운 문제를 해결해야 할 때 데이터를 확보하는게 가장 어려운 일입니다. 머신러닝에서는 이를 Cold-start 문제라고도 하는데요. 최근에 GPT-3나 T5 같은 대형 언어 모델을 통해 학습 데이터를 생성하는 방식이 각광을 받고 있습니다.
하이퍼클로바도 역시 비슷한 방식으로 사용할 수 있는데요. 실제로 대화시스템의 유저 인텐트(intent) 분류에서 이러한 방식으로 매우 적은 데이터로 시작해, 하이퍼클로바로 데이터를 뿔리는(?) 방식으로 AI 모델 개발을 더 효율적으로 할 수 있다는 비전을 보여주고 있습니다.
오늘은 최근 공개된 하이퍼클로바를 살펴보았습니다. 네이버 서비스에 앞으로 어떻게 적용될 것인지 지켜보는 것이 무척 흥미로울 것 같습니다. 이러한 대형 모델을 기반으로 AI 서비스를 개발하는 것이 피할 수 없는 흐름인 것 같습니다. 그렇기 때문에 이 주제에 대해 좀 더 파보는 것도 재밌을 것 같다는 생각이 드는데, 이번 글을 어떻게 읽으셨는지 댓글로 알려주시면 감사하겠습니다!
그리고 감사하게도 네이버 연구진/개발자 분들이 2021년 5월에 하이퍼 클로바에 대해서 더 깊게 Naver AI NOW라는 컨퍼런스를 통해 이야기해주셨습니다. 저도 관심있는 부분 위주로 재미있게 청취하였는데, 아직 발표 영상이 홈페이지에 나와있으니 관심 있으신 분들은 논문과 함께 참고하시면 좋을 것 같습니다.






