Week 42 - 사물 인식 모델의 한계를 NLP로 깨부수는 CLIP!


Week 36에서 AI가 인간 수준으로 세상을 이해하려면 단순히 텍스트 뿐만 아니라 여러 가지 인지(Perception) 데이터를 다룰 수 있어야 한다고 얘기를 하였습니다. 이것의 첫걸음은 텍스트와 이미지를 함께 이해하는 모델을 만드는 것이죠.
그래서 Week 40부터는 NLP과 Computer Vision 함께 다루는 연구에 대해 소개하고 있습니다. 이렇게 텍스트와 이미지 같이 다른 형태의 인풋을 함께 다루는 문제를 멀티 모달(Multi-modal)이라고 하는데, 점점 더 이러한 연구가 더 주목받고 있습니다.
GPT를 만든 OpenAI에서도 이러한 방향을 추구하고 있습니다. 세상을 놀래키게 한 GPT-3를 공개한지 얼마 안되어 <CLIP: Connecting Text and Image>라는 연구를 2021년 1월 공개하였습니다.
지난주에 소개시켜드린 DALL-E와 같은 날 공개된 이 연구는 마이크로소프트 오피스에 CLIPPY와는 연관성이 없는 제품입니다..! (이걸 아시는 분은 나이대가..?)
CLIP은 여태까지 나온 사물 인식 분류 모델의 틀을 깨부순다는 점에 있어서 매우 획기적인 연구입니다. 특히 기존의 사물 인식 모델들은 아무리 잘 학습시켰어도 비슷하지만 재학습하지 않고 새로운 문제에 적용시키는 것이 쉽지 않았는데요.
CLIP은 새로운 학습 방법과 텍스트 데이터를 이용해 이러한 단점을 극복해냅니다. 이미지 사물 인식을 위해서 어떻게 텍스트를 활용한다는 것일까요?
이 글에서는 CLIP 모델을 해부해보도록 하겠습니다. 또한 최근에 한국어 버전의 CLIP (KoCLIP)을 학습시키고 오픈소스로 공개한 팀이 있어 이 분들의 질의응답 인터뷰도 진행하였습니다.

기존 분류 모델(classification model)의 한계
머신 러닝에서 분류 문제(Classification)이란 어떤 데이터가 주어졌을 때, 어떤 분류에 속하는지 확률적으로 계산해내야 하는 문제입니다. 단순하게 두 가지 분류가 있다면 이분 분류(Binary Classification)이고, 그 이상의 N개가 있으면 멀티클라스 분류 문제라고 Week 6 과 Week 8 에서 설명하였습니다. 어떤 이메일이 주어졌을 때, 스팸인지 아닌지 판단하는 분류 모델(Classifier)은 어떻게 만드는지 간단히 알아보았지요.
가장 대표적인 데이터 셋이 숫자 손글씨 MNIST입니다. 숫자는 0~9까지 총 10 가지 분류 중 한개일 수 밖에 없겠죠. 이처럼 분류 모델은 주로 가능한 결과(output)가 정해져있습니다.

다른 이미지 데이터 셋도 대부분 마찬가지입니다. 한번쯤을 들어봤을 CIFAR10 / CIFAR 100에서 10과 100은 이미지 분류의 종류가 총 몇 개인가를 뜻합니다.

이처럼 분류가 정해져있는 것을 레이블 스페이스(label space)라고도 하고, 데이터 스키마(data schema)라고도 불립니다. 분류 모델은 소프트맥스 레이어(Softmax layer)를 통해 모델링됩니다. 최종적으로 10개의 분류 중에 어떤 것이 맞는지 확률을 예측하도록 학습이 됩니다.
근데 만일 갑자기 고객이 와서 10개가 되서 좋으니 11번째 분류 - 예를 들어, 거북이 - 를 추가해달라고 하면 어떻게 해야할까요? 아니면 고양이 분류를 좀 더 세분화해서 고양이 종을 세세히 분류해달라고 하면 어떻게 해야 할까요?
실제로 머신러닝 개발을 하다보면 이런 식으로 요구 조건이 바뀌는 경우가 굉장히 흔할 것이라고 생각합니다.
현재 분류 모델 구조에서는 모델을 재학습시키는 것이 일반적입니다. 레이블도 바뀌기 때문에 데이터 저장과 전처리도 다시 해야할지도 모릅니다. 이렇게 레이블 스페이스가 지속적으로 바뀌는 환경이라면 이러한 과정을 반복하는게 굉장히 시간과 돈적으로 비용이 많이 드는 문제가 생깁니다.
이러한 단점을 극복하려고 나온 모델이 CLIP입니다.
CLIP과 기존 분류 모델의 가장 큰 차별점
CLIP과 기존 이미지 분류 모델의 가장 큰 차별점은 레이블 스페이스에 대한 이해입니다. 소프트맥스 레이어를 사용하는 분류 모델은 레이블 이름에 대한 이해가 전혀 없고, 전부 그냥 숫자로 치환해버립니다. "airplane"이 뭔지, "dog"가 뭔지, "cat"이 뭔지 전혀 알지 못합니다. 그저 dog는 주어진 10개의 분류 중에 6번째라고 모델링되어 있는 것입니다.

만일 새로운 레이블로 들어온다면? 사실 11번째 분류로 거북이(turtle)이 들어오든 기차(train)가 들어오든 분류 모델에게는 큰 차이가 없습니다.
그런데 곰곰히 생각해보면 사람이라면 레이블 이름만 보더라도 turtle은 frog에 좀 더 가깝고, train은 airplane이나 automobile에 더 가까울거라는 예상을 할 수가 있습니다. 이처럼 텍스트인 레이블 이름에는 분류에 도움이 될만한 세상에 대한 지식이 포함되어 있다는 것을 알 수 있습니다.
다만 현재의 이미지 분류 모델은 모든 레이블 스페이스를 숫자로 바꿔버리면서 이 지식을 사용하지 못합니다. 3과 11은 그저 순서의 차이일뿐이죠.
CLIP: 레이블 텍스트를 지식으로 활용해보자
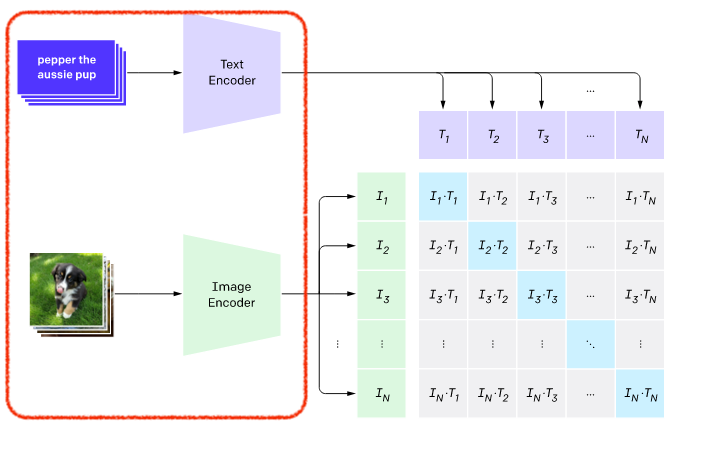
반면 CLIP은 이미지와 텍스트를 모두 인풋으로 사용합니다. 특히 텍스트는 한 단어 이상이어도 됩니다. OpenAI 답게 스케일 있게 인터넷에서 4억 개 (400M)의 이미지와 이를 설명하는 텍스트 쌍의 데이터를 구축하였습니다. 이는 GPT-2 학습시킨 텍스트 데이터와 맞먹는다고 하는데요. 이렇게 CLIP은 많은 이미지와 텍스트로 학습이 되었습니다.
데이터의 형태는 앞서 공부한 이미지에 자막을 생성하는 문제 (Image Captioning)과 동일합니다.

OpenAI 연구 팀에서는 처음에는 seq2seq 모델로 이미지를 넣으면 텍스트를 출력하는 식으로 구조를 짜 학습시켜보았다고 합니다. 그런데 기존의 분류 모델보다 seq2seq는 매우 비효율적입니다. 모델 사이즈도 크고 학습 시간/예측 시간도 깁니다.
어떻게 좀 더 효율적으로 해야 할까 고민하다가 대비 학습(Contrastive Learning)이라는 방식을 채택합니다.
(CLIP의 이름은 Constrastive Language-Image Pre-training)
대비 학습(Contrastive Learning)이란?
Contrastive Learniing이란 두 개의 데이터가 주어졌을 때 비교를 하는 식으로 모델을 학습하는 방식입니다. 예를 들어, 두 개의 이미지를 주고 같은 분류인지 아닌지 모델이 구분할 수 있게 학습을 시키는 것이지요.

이러한 학습 방식의 장점은 대략적인 분류만 있어도 데이터를 학습에 쓰일 수 있다는 점입니다. 그래서 최근에 셀프 지도 학습(self-supervised learning)이나 비지도 학습(unsupervised learning)에도 많이 쓰였었죠.
CLIP은 이미지와 텍스트가 주어졌을 때, 이 이미지와 텍스트 설명이 알맞는지 아닌지 대비하는 식으로 학습됩니다. 특히 학습 데이터를 만드는 방식이 매우 간편한데요.
N개의 이미지-텍스트 쌍, 여기서 N=3로 가정해봅시다. 그러면 텍스트 3개, 이미지 3개일텐데, 짝을 지어주면 9쌍(N^2)이 나오겠죠. 그 중에 참인 쌍은 3개(N), 거짓인 쌍은 6개(N^2 -N). 요렇게 9개의 학습 데이터 포인트를 만들 수 있습니다.
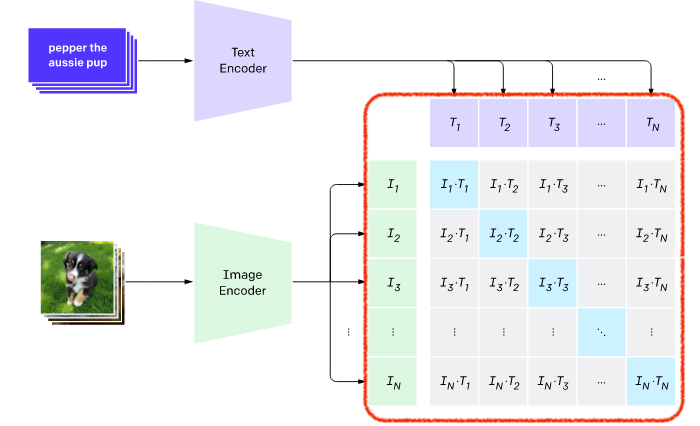
이렇게 학습된 CLIP 모델은 결국 이미지와 텍스트가 주어졌을 때, 이 두개가 서로 참인 쌍인지 아닌지를 0~1사이의 숫자로 표현할 수 있습니다. 이 숫자는 확률이라고 해석해도 되고, 점수라고 해석해도 좋습니다. 쉽게 말해 텍스트와 이미지의 궁합 점수입니다.
이렇게 대비 학습을 사용하였을 때 seq2seq 모델로 하였을 때보다 3~4배 정도의 효율을 보여주었다고 합니다.
CLIP 활용 방법: 제로 샷 러닝
제로 샷 러닝(zero-shot learning)은 Week 30에서 GPT가 왜 기존의 연구와 다른가를 설명하면서 나온 개념입니다. 새로운 데이터 셋이 나왔을 때, 모델을 재학습하지 않고도 예측을 제법 잘하게 하는 기법을 제로 샷 러닝이라고 합니다.
CLIP도 OpenAI의 자식답게 제로 샷 러닝을 염두에 두고 만들었습니다.
예를 들어, CIFAR-10처럼 10가지 분류라면 각각 그럴듯한 그림 설명체로 변환합니다.
"A photo of {airplane, automobille, bird, cat, deer, dog, frog, horse, ship, truck}"
"이것은 {비행기, 자동차, 새, 고양이, 사슴, 개, 개구리, 말, 배, 트럭}이다"
이렇게 10개의 텍스트 후보를 주고 이미지와 함께 CLIP에게 물어보면, 위에 설명한 점수가 각각 나오겠죠? 그 중 가장 점수가 크게 나온 텍스트를 최종 분류로 채택합니다. 참 쉽죠?
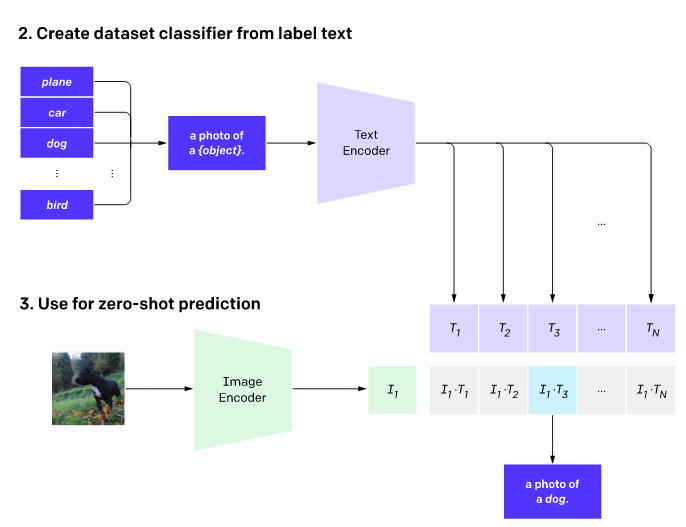
여기서 장점은 같은 데이터라도 11번째, 예를 들어, 나는 고양이나 강아지 말고 거북이도 찾고 싶다 하면 텍스트 후보에 "이것은 거북이이다"를 추가해주면 됩니다. 모델을 재학습해야 하는 것보다 훨씬 더 간편합니다.
CLIP은 수많은 이미지 데이터 셋에서 재학습하지 않는 제로 샷 러닝 성능이 꽤 잘 나왔습니다.
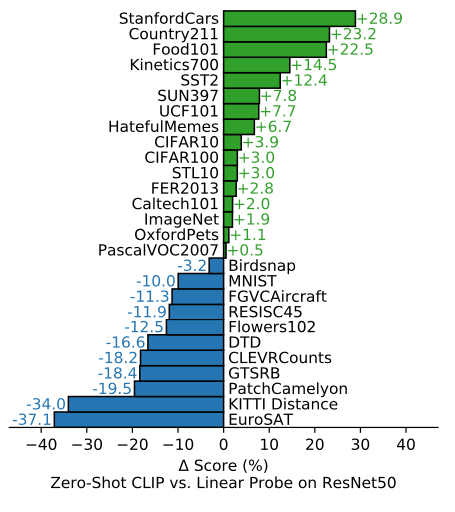
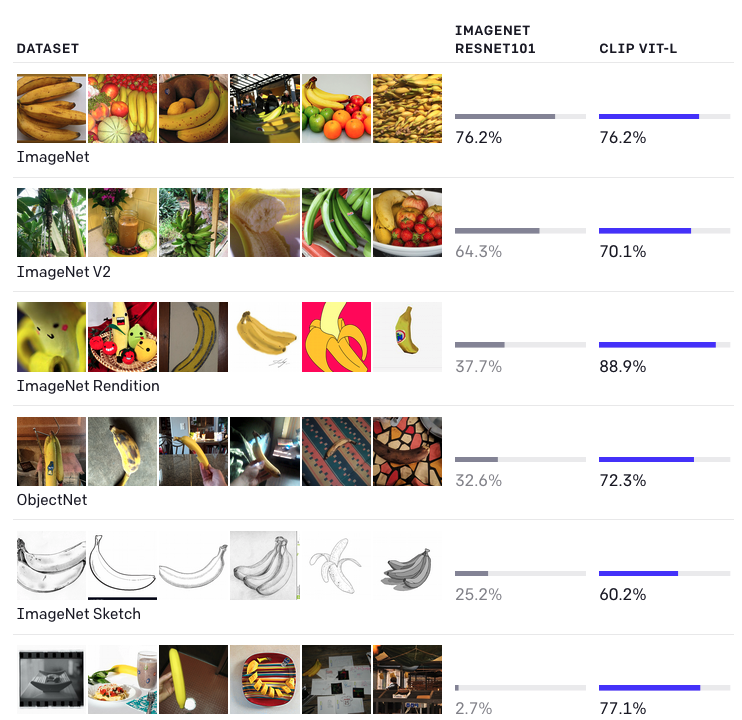
다만 좀 어렵거나 특정한 도메인의 문제(의료 데이터인 암종양 분류, 위성 사진 등)에서는 좋은 성능을 보이지 못했습니다. 간단한 사물인식 하는 데이터에선 비슷하거나 더 나은 성능을 보여줍니다.
특히 CLIP은 *domain/distribution shift에 강합니다. 블로그에서는 다양한 바나나의 그림을 보여주는데요. 제품 사진으로 찍은 바나나로 학습된 모델이 그림 스케치나 일상 사진으로 찍힌 바나나 사진을 잘 분류하지 못하는 반면 CLIP은 이러한 경우에도 강합니다.
(*이렇게 사람이 보기에는 비슷한데 전반적인 데이터의 특성이 바뀌는 경우를 domain/distribution shift라고 부릅니다. 꽤나 많은 머신러닝 모델들이 이러한 것에 약합니다.)
한국어 버전의 CLIP은 없을까요?
있습니다! 최근에 한국어 버전의 CLIP (KoCLIP)을 학습시키고 오픈소스로 공개한 팀이 있어 모시고 인터뷰를 진행해보았습니다. 먼저 이 주제를 저에게 제안해주셨는데 너무 감사드립니다!
 jaketae
jaketaehttps://huggingface.co/spaces/flax-community/koclip
간단하게 자기소개 부탁드립니다.
안녕하세요, 연세대학교 언더우드 국제대학에서 경제학을 전공하고 있는 손규진, 예일대학교에서 컴퓨터공학을 전공하고 있는 태재성, 국내금융회사 AI연구원으로 일하고 있는 박한솔, AWS AI에서 엔지니어로 재직중인 오민식 입니다.
HuggingFace와 Google Cloud Platform이 공동 주관한 Flax-Community-Week에 대해서 소개해주실 수 있으신가요?
Flax-Community-Week는 HuggingFace 와 Google Cloud,Flax,Jax 팀의 주관하에 기존 보다 더욱 다양한 NLP, CV 분야의 대규모 모델을 개발하고 오픈소스로 공개하고자 개최 되었습니다. 제한된 시간 내에 연구 제안서와 팀원 모집을 완료한 그룹에 한해 TPUv3-8 VM을 제공해 주었으며, 참가 팀은 이를 바탕으로 약 2주간 개발과 모델 학습을 진행했습니다.
총 151개의 팀, 약 800명의 연구자 분이 참여했으며, 그 결과 매우 다양한 언어와 데이터셋으로 학습된 모델들이 공개 되었습니다. DALL-E, GPT, ByT5, CLIP 등 비교적 최근에 공개되어 주목을 받은 논문들에 대한 구현체들 역시 매우 다양하게 개발되었고, 관련 분야에 관심이 있으신 분들은 꼭 한번 찾아보시면 좋을 것 같습니다.
저희 KoCLIP 팀 이외에 CLIP+NeRF팀 역시 한국 연구자 분들이 참여하셨는데 3D Neural Rendering, Few-Shot Learning 분야를 공부하고 계신 분들은 이 프로젝트도 꼭 확인해보시길 추천드립니다.
많은 연구 중에 CLIP을 선정하게 된 계기가 무엇인가요?
해당 연구를 제안하게 된 태재성, 손규진입니다. 저희는 KoCLIP에 앞서 ColorBERT 라는 토이 프로젝트를 진행했고, 해당 프로젝트에서 BERT가 일반 상식, 그 중에서도 색깔에 대해 학습이 덜 되어 있다는 사실을 확인 할 수 있었습니다. 이에 ColorBERT 프로젝트에서 직접 데이터셋을 수집하고 RoBERTa 모델에 Sensory-FineTuning을 진행했지만 아쉽게도 기대한 수준의 성능 개선을 달성하지는 못 했습니다. 의미 있는 발견을 도출 해 낼 수는 없었으나 감각기관이 제한된 언어 모델로는 한계가 있음을 깨달았고, 이는 “멀티모달한 언어모델”이라는 테마에 대해 관심을 갖게 되는 계기가 되었습니다.
이에 영향을 받아 Flax-Community-Week를 위한 연구주제를 선정하는 과정에서 시각적인 정보 역시 학습에 활용하는 멀티모달한 모델들에 관심을 가지게 되었고 그 중 구현 가능성 등 여러가지를 고려해 CLIP 모델을 개발하기로 결정했습니다.
본래 영어 모델인 CLIP을 한국어 버전으로 만들기 위해 어떤 과정을 거쳐야 했나요?
웹 크롤링을 통해 손쉽게 모은 텍스트 데이터를 Semi-Supervised 형태로 사용할 수 있는 기존의 언어 모델과 달리, CLIP의 경우 학습 과정에서 대규모의 텍스트-이미지 데이터 쌍을 필요로 했고 저희는 제한된 시간 내에 충분한 양을 확보할 수 없다고 판단해 대체적인 방법을 택하게 되었습니다. CLIP은 각기 다른 이미지와 텍스트 인코더의 임베딩을 하나의 공통된 잠재 공간 (representation space)에 투사하는 방식을 사용합니다.
데이터가 충분한 경우엔 두 개의 인코더가 처음부터 같은 잠재 공간을 사용하도록 학습을 시키겠지만, 저희가 사용한 Ai Hub의 MS-COCO 이미지 캡션 데이터셋은 4만 장에 불과했고 이에 사전학습된 이미지, 텍스트 인코더 모델을 불러와서 파인튜닝(fine-tuning)하는 방법을 사용했습니다.
이때 텍스트 인코더는 klue/Roberta-Large 모델을, 이미지 인코더는 openai/clip-vit-base-patch32 모델과 google/vit-large-patch16-224를 사용했는데, 이미지 인코더의 종류가 후에 KoCLIP-Based와 KoCLIP-Large를 구분하는 기준이 되었습니다. 저희와 같이, 따로 사전학습된 모델을 사용하는 경우 두 모델의 출력은 서로 상이한 잠재공간을 사용해 해당 출력들을 공통된 잠재공간에 존재하도록 변환해 줄 프로젝션 레이어를 추가로 학습해야만 합니다. 결과적으로 위에서 언급한 파인튜닝은 이 프로젝션 레이어를 학습하는 과정으로 볼 수 있을 것 같습니다.
여러 명이 하나의 머신러닝 프로젝트의 코드 베이스, 특히 오픈 소스로 공개될 코드를 작업하는 것에 대한 조언, 어려운 점, 재밌는 점이 있으신가요?
(손규진)
본 프로젝트는 디스코드를 통해 진행이 되어 저희 팀 뿐만 아니라 다른 팀의 진행사항 역시 실시간으로 계속 볼 수 있었습니다. 저보다 경험이 풍부한 분들이 연구를 이끌어 나가는 과정을 관찰하는 것은 논문과 코드를 읽으며 배울 수 있는 것과 그 종류가 매우 상이한데 그런 노하우를 알아가는 좋은 기회가 되었습니다.
나아가, 오픈소스로 공개될 코드를 작업한다는 것은 Community에 기여할 수 있다는 설렘과 다수의 사람들에게 평가를 받을 수도 있다는 떨림이 공존하는 일인 것 같습니다. 이러한 것들이 더욱 신경써서 개발을 진행하는 동기 부여가 되었고 프로젝트의 배포가 완료된 이후에는 더 큰 성취감을 느낄 수 있었던 것 같습니다.
(태재성)
다수의 인원이 하나의 프로젝트에 일한다는 것은 어렵지만 또 굉장히 보람찬 일입니다. 특히 저는 12시간의 시차를 넘어서 협업한 것이 가장 기억에 남습니다. 누군가가 커밋을 해두면 자고 일어나서 확인하고, 또 작업 후 디스코드에 진행경과를 남기고 자러가면 다른 누군가가 이어서 작업을 하는 일련의 과정을 통해 협업의 보람을 느낄 수 있었습니다. 물론 질문이 있을때 바로 물어볼 수 없다는 단점이 있지만, 이 점을 모두가 인지하고 있기 때문에 주석, 커밋 메세지, 그리고 디스코드를 적극 활용하여 서로가 다른 사람의 코드도 쉽게 알아볼 수 있도록 더 신경쓴 것이 아닐까 생각합니다.
이번 Community-Week의 평가 기준 중 하나이기도 했지만, 오픈소스로 코드를 공개할 때 가장 중요한 것은 문서화라고 생각합니다. 해당 프로젝트에 대한 소개, 사용한 데이터, 실험 과정과 결과까지, 모든 것을 투명하고 재현 가능하도록 하는 것이 오픈 소스의 철학이라고 할 수 있습니다. 물론 저희 코드베이스에도 학습 스크립트는 TPU 접근을 가정하고 짜여있기 때문에 누구나 바로 실행할 수는 없기에 개선의 여지가 있습니다. 하지만 근래 머신러닝 커뮤니티에서 강조되고 있는 오픈소스의 철학에 대해 보다 깊게 생각해볼 수 있는 소중한 기회였다고 생각합니다.
(오민식)
저의 경우는 해당 프로젝트 외에도 다른 프로젝트를 리드하며 동시 진행했었는데 외부 연구자들이 참여한 오픈 소스 리서치 프로젝트를 이끌어 보며 수상도 할 수 있었던 좋은 경험이었습니다. 여러 명이 참여 하는 오픈 소스 프로젝트를 진행할때는 서로 작업 기대 결과를 꾸준히 싱크하고 그에 대한 피드백을 상세히 공유하는 것이 좋은 작업 결과물을 위해 중요하다고 생각합니다. 구성원의 니즈와 프로젝트에서 기대하는 바를 캐치하여 원하는 기술을 활용해볼 수 있는 playground를 제공하는 것도 참여 구성원의 동기를 불러일으키는데 중요한 부분 입니다. 오픈 소스 프로젝트 진행은 즐겁게 참여하며 많이 배우고 또한 ML Community에 대한 기여와 완성된 프로젝트 공개의 보람을 느낄 수 있다는 부분이 매우 매력적 입니다.
북미에서 한국에 계신 다른 분들과 함께 24시간 열심히 협업한 것이 즐거웠습니다. 특히 다들 본업이 있으실 텐데 열정을 가지고 임해주셔서 저도 재밌게 참여한 듯 합니다.
(박한솔)
저도 재성님과 동일하게 시차를 넘나드며 협업한 것이 가장 기억에 남습니다. 제가 밤새서 특정 일을 수행하면 아침에 다른분이 그 결과물을 받아 또 다른 업무를 수행하시는 등 바톤터치하며 프로젝트가 앞으로 나아가는것이 흥미로웠습니다. 앞으로 또 기회가 있으면 KoCLIP 멤버분들과 프로젝트를 진행하고 싶습니다.
CLIP 모델을 실제 어떤 문제에 응용할 수 있을까요?
CLIP은 이미지와 텍스트 사이의 유사도를 추론하는 모델입니다. 저희 데모에서 볼 수 있는 것처럼, 텍스트 기반 이미지 리트리벌(image retrieval)이 가장 기본적인 응용일 것입니다. 여러 장의 이미지가 있을때, CLIP이 텍스트 쿼리에 가장 알맞는 이미지를 출력해주는 것이죠.
하지만 이외에도 CLIP의 응용 가능성은 무궁무진합니다. 꼭 이미지와 텍스트가 아니더라도, 서로 다른 도메인에 있는 인코더를 여러 개 가져와서 서로의 관계를 학습하게 한다면, 도메인 A의 쿼리로 도메인 B의 정보를 리트리벌할 수 있는 시스템을 구축할 수 있습니다. AudioCLIP에서 볼 수 있듯이, 2개 이상의 도메인의 인코더를 같이 학습시킬 경우, 훨씬 복잡한 멀티모달한 관계도 모델링할 수 있습니다.
DALL-E에서 볼 수 있듯이, 이미지 생성 모델에서도 CLIP은 생성된 후보군 중 가장 유력한 이미지를 선별하는 심판과 같은 역할도 수행할 수 있습니다.
앞으로는 어떤 프로젝트/일을 준비 중(아니면 하고 싶은) 있으신가요?
(태재성)
스타트업에서 인턴을 마무리하고 복학할 준비를 하고 있습니다. 학업에 열중하겠지만, 현재로서 참여하고 있는 또 다른 프로젝트는 Hugging Face가 진행하고 있는 Big Science라는 프로젝트입니다. OpenAI가 GPT-3를 공개한 이후로 거대 언어 모델에 대한 관심이 늘고 있는데요, EleutherAI의 GPT-Neo나 네이버의 HyperClova처럼 Hugging Face에서도 거대 언어 모델을 기획하고 있습니다. 차이점 중 하나라면 해당 모델은 multilinguality를 염두해두고 설계되고 있다는 점입니다. 개인적으로 어떤 결과물이 나올지 굉장히 궁금합니다.
앞으로 더 깊이 공부하고 싶은 분야는 생성 모델입니다. 익히 알려진 GAN, VAE, Flow외에 최근에 많은 관심을 받고 있는 Diffusion Model까지, 모두 이미지나 음성 생성 분야에서 많이 쓰이고 있기에 이쪽으로 연구해보고 싶다는 생각을 하고 있습니다. 이런 모델은 연속적인 데이터를 가정으로 하는데, 이를 어떻게 NLP와 같이 퀀타이즈 되어있는 데이터에 응용할 수 있을지도 연구해보고 싶습니다.
(오민식)
Distillation에 관심이 많습니다. 그 외에도 Language Model 관련 주제로 연구를 이어나갈 예정입니다.
(손규진)
저는 한동안 NLP에 국한되어 있었던 제 관심사를 넓혀 나갈 예정입니다. 최근에는 GNN과 Offline-RL 분야의 논문들을 읽어 보는 중이며 그 중에서도 Graph Attention Networks, Decision Transformer와 같은 논문들이 아무래도 좀 더 친숙하게 다가오는 것 같습니다. 저도 곧 개학이라 한동안 경제학과 학부생 신분으로 돌아가 공부를 하겠지만 가능하다면 다른 도메인에서 사용되고 있는 Transformer 아키택처를 공부하고 발전시키는 연구를 해보고 싶습니다.
저희 모두 소속과 관심이 달라 가까운 미래에 협업하기에는 어려움이 있을 것 같지만 언제가 또 함께 연구할 일이 있으면 좋을 것 같습니다 :)
(박한솔)
사람들이 많이 사용하는 NLP 서비스를 개발하고 싶습니다. 최근에 챗봇과 검색에 최신 NLP 활용해 성능을 향상시키는 방법을 연구하고 있습니다.
jaketae오늘은 CLIP 모델에 대해 알아보고 KoCLIP 프로젝트 팀원 분들과도 이야기해보았습니다. 각자 다른 곳에서 이런 오픈소스 프로젝트를 하는 4분이 너무 멋지고 부럽다는 생각이 들었네요.
저도 이 멀티모달 시리즈를 쓰면서 많이 공부하면서 글을 쓰고 있어 매우 유익한 시간을 보내고 있습니다. 제가 새로 배우고 이해한 것이 여러분께도 잘 전달되었으면 좋겠습니다.
계속 이렇게 협업 컨텐츠도 이어나갈 예정이니 혹시 <위클리 NLP>에 소개하고 싶은 논문이나 프로젝트가 있으면 댓글이나 메일로 연락바랍니다!

Reference
- Radford et al., 2021, Learning Transferable Visual Models From Natural Language Supervision
- OpenAI Blog, CLIP: Connecting Text and Images



