Week 43 - 벤치마크 데이터 셋 그리고 KLUE


인간사는 경쟁을 빼놓고는 이야기할 수 없습니다.
큰 패권 국가 간의 전쟁만 보아도 역사의 흐름을 파악할 수 있습니다. 평화의 화합의 장이라는 올림픽도 결국 전세계 각 국가에서 엄청난 경쟁을 뚫고 온 선수들의 최종 대회입니다. 이번 올림픽 때는 금메달 지상주의가 좀 줄어들었다고 하지만, 승리한 선수들이 더 많은 스포트라이트를 받게 되는 건 어쩔 수 없는 것 같습니다. 옛날 유행어 중 하나인 "1등만 기억하는 더러운 세상!"이라는 개그맨의 외침이 기억이 나네요.
머신러닝 분야도 이와 마찬가지입니다. 바로 벤치마크 데이터 셋(benchmark dataset) 때문이죠. 1980년대 후반 처음 등장한 이 개념은 머신러닝 분야가 지금까지 놀라운 발전을 할 수 있도록 한 원동력입니다. 지금은 머신러닝에 입문하거나 및 고수들이 실력을 겨누기 위해 많이 시작하는 플랫폼, 캐글(Kaggle)을 통해 이러한 대회가 익숙하지만, 이렇게 되기 까지는 꽤 많은 시간이 걸렸습니다.
이번 <위클리 NLP>에서는 벤치마크 데이터 셋이 무엇이고, 왜 중요한지, 어떤 한계가 있는지 등에 대해 이야기해보겠습니다. 그리고 최근 공개된 한국어 NLP 벤치마크 데이터 셋 KLUE를 소개합니다.

벤치마크 데이터셋이란?
머신러닝 모델을 평가하기 위한 데이터 셋으로는 항상 학습 셋(train) / 평가 셋(test)으로 나뉩니다.

이것은 통계학적으로 유의미한 평가를 하기 위함입니다. 모델 학습에 사용되지 않은 새로운(fresh)하고 충분히 큰 평가 셋은 그 모델의 성능과 리스크를 편향되지 않게 측정하기 적합합니다. 여기서 핵심은 "새롭다는" 것인데요, 전에도 강조했던 것처럼 학습과 평가 셋을 만들 때 어떠한 겹치는 부분이 있어서는 안됩니다.
실전에서는 이게 생각보다 쉽지 않습니다. 예를 들어, 데이터 자체는 겹치지 않으나 데이터 생성/라벨한 크라우드 워커는 겹치는 등.. 처음 디자인할 때 이를 염두에 두고 만들어야 합니다.
이러한 train-test 패러다임은 전부터 존재했으나, 벤치마크 데이터 셋은 1980년대 후반 처음 등장합니다. 특정한 머신러닝 문제를 공통된 데이터를 통해 여러 연구자들끼리 공유하여 해결하기 위해 만들기 시작한 것이 시초입니다. 전에는 알아서 데이터를 나눴어야 했지만, 나중에는 비교를 위해 정확히 어떻게 나누어져 있는 지까지 공유가 되는 방식으로 바뀌었습니다.
최근에 재미있게 읽고 있는 머신러닝 개념서 Patterns, Predictions, and Actions에서는 역사 상 첫 벤치마크 데이터 셋은 음성 인식 문제의 TIMIT이라고 합니다. 다른 성별, 지역의 미국 영어 스피커들의 음성과 문장 글을 포함한 이 데이터 셋은 국방 고등 연구 기획청(DARPA)에서 요청하여 MIT, TI 등의 연구 기관에서 만들었습니다. 저도 전에 음성 관련 일을 할 때 이 데이터 셋을 사용해본 적이 있는데요.
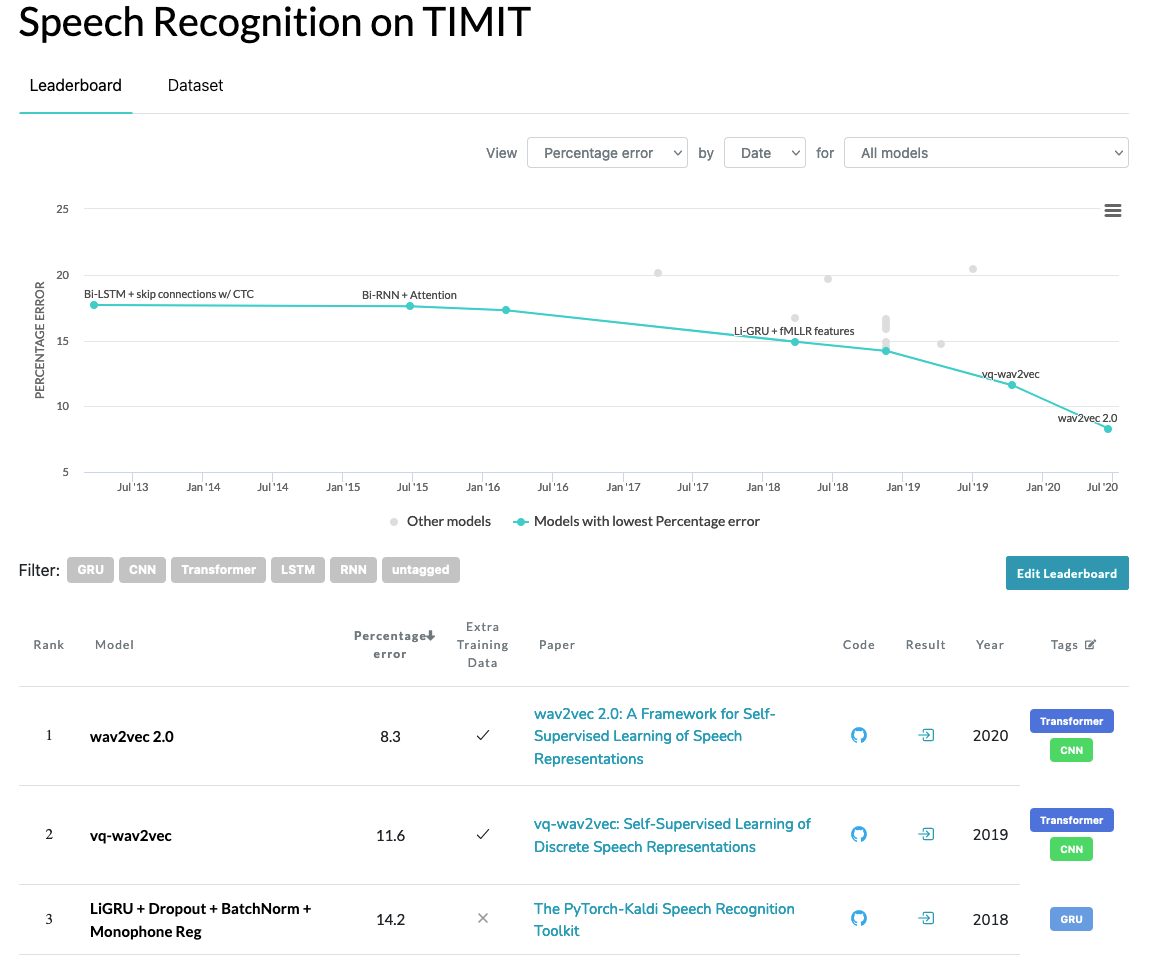

중요성
이처럼 벤치마크 데이터 셋은 연구자들끼리 경쟁을 유도한다는 점에서 머신러닝 발전에 무척 중요하다는 점을 알 수 있습니다. Patterns, Predictions, and Actions에서는 벤치마크 데이터 셋의 중요성을 이렇게 요약합니다.
- 단지 데이터만 제공하는 것이 아니라, 문제와 해당 데이터의 정확한 정의에 대한 합의가 이루어진다.
- 두 가지 연구에 대해 정확한 비교를 제공해준다. 이 때문에 벤치마크 데이터 셋을 중심으로 아이디어 교환, 연구 경쟁 등이 이루어지는 커뮤니티가 형성된다.
- 업계(industry)와 학계(academia) 간의 지식 교환 수단이 된다. 실제로 학계에서 만들어진 여러 벤치마크 데이터 셋을 많은 기업 연구 팀들이 사용하면서 더 많은 발전을 이루고 있습니다.
- 데이터와 함께 이를 전처리하는 코드, 베이스 라인 모델 등이 함께 오픈소스로 공개 되면서 입문자들에게 큰 도움이 된다.
이처럼 벤치마크 데이터 셋을 머신러닝 학계가 올림픽 같은 평화와 화합의 장이면서, 피 튀기는 경쟁의 장이 되도록 만드는데 큰 기여를 하였습니다.
논문을 읽다보면 한번 쯤은 들어봤을 유명한 벤치마크 데이터셋을 몇 개 소개하자면:
- NLP: GLUE (자연어 이해), SqUAD (독해), SST (감성 분석) 등
- 컴퓨터 비전(CV): MNIST (OCR 숫자 인식), ImageNet (사물 인식) MS COCO (사물 인식, 세그멘테이션, 자막 등) 등
이 있습니다.

(Fei-Fei Li 교수가 ImageNet 프로젝트에 대한 의 비하인드 스토리 이야기하는게 무척 흥미로웠습니다!)
 The Robot Brains Podcast
The Robot Brains Podcast한계점/문제점
벤치마크 데이터 셋은 많은 발전을 이루었지만 몇 가지 한계점과 문제점을 안고 있기도 합니다.
가장 중요한 점은 앞에서 평가 셋의 핵심, "새로움(freshness)"입니다. 이론적으로는, 평가 셋은 정말 마지막에만 사용되어야 합니다. 왜냐하면 평가 셋의 에러를 보고 다음 모델 개선에 이 정보를 쓴다면 더이상 평가 셋의 새로움이 사라지고, 통계학적인 독립적 유의미성이 무너지기 때문입니다. 오답 노트를 만들어 보고 같은 시험을 다시 보면 안되겠죠.
조경현 교수님도 강의 노트의 결론에 굉장히 강조를 하셔서 Week 12에 이어 한번 더 인용합니다.
"I would like to emphasize is the importance of not looking at a held-out test set. One must always select anything related to learning, e.g., hyperparameters, networks architectures and so on, based solely on a validation set."
Kyunghyun Cho, Chapter 7: Final Words, Natural Language Understanding with Distributed Representation
다만 현실적으로 이게 엄격하게 지켜질 수가 쉽지 않습니다. 연구를 하다보면 왜 본인의 모델이 잘 안되는지 평가 셋을 뜯어보는 경우가 많거든요. 그렇기 때문에 많은 연구자들은 현재 선두를 달리는 모델들이 벤치마크 데이터 셋에 오버핏(overfit)이 되어 있을 확률이 높다는 지적을 합니다.
벤치마크 데이터 셋이 오래 될수록, 리더보드 경쟁이 치열해질수록 이러한 경향이 더 클 것이라고 생각됩니다. 그렇기 때문에 주기적으로 벤치마크 데이터 셋을 리프레쉬해줄 필요가 있는데요. SQuAD가 1.0에서 2.0으로 업그레이드 된 것이 좋은 예입니다. 이미 많은 연구자들이 쓰고 있어 관성이 있는 데이터 셋을 바꾸자고 설득하는게 쉽지만은 않을 것 같습니다. 비용과 시간 문제도 있고요. 너무 자주 바뀌면 "벤치마크"라는 의미도 퇴색될지도 모르겠습니다.
최근에 "어떻게 하면 자연어 이해 벤치마크 데이터 셋을 고칠 수 있을까?"라는 도발적인 제목을 가진 논문을 인상 깊게 읽었습니다.
이 논문 역시 이러한 점을 지적합니다. 특히 몇몇 모델들은 좀 더 현실과 비슷한 다른 데이터를 가져다가 선두 모델들에 테스트를 해보았는데, 좋지 않은 성능을 보여주었다고 합니다. 마치 공부는 열심히 한 토익과 토플은 만점이지만, 현지인과의 영어 대화는 잘못하는 범생이 같은 느낌입니다.
이 외에도 이 논문과 Patterns, Predictions, and Actions에서는 몇 가지 다른 문제/한계점을 조심해야 한다고 하고 있습니다.
- 데이터 수집 가이드라인의 잘못된 설계 때문에 생기는 원치 않은 편향성
- 현실 데이터와의 괴리감. 이를 극복하기 위해 데이터의 다양성/현실성을 어떻게 장려할 것인가
- 크기에서 오는 통계학적 파워. 너무 작은 데이터 셋은 통계학적 유의미한 평가를 만들기 힘들지만, 데이터 수집은 비싸다.
- 데이터의 개인 정보 유출, 저작권 문제 (ex. 넷플릭스 챌린지 데이터 셋의 개인정보 유출 사건)
여기서 다 다루지는 못하지만 관심이 있다면 레퍼런스에 있는 원 논문과 책을 참고하시길 바랍니다.
KLUE: 한국어 언어 이해 평가
KLUE: Korean Language Understanding Evaluation는 최근에 공개된 한국어 NLP 벤치마크 데이터 셋입니다. 이 규모로는 처음 나온 한국어 NLP 벤치마크라 큰 주목을 받았고, 여러 한국어 연구자들 분들이 모여서 함께 해낸 연구라 더더욱 멋집니다.
이미 Pretrained 한국어 언어 모델도 포함한게 또다른 큰 특징입니다. 이러한 언어 모델은 한국어 NLP 커뮤니티에게 아주 귀중하고 중요한 리소스가 될 것입니다.

이 데이터 셋이 한국어 NLP의 큰 발전 원동력이 될 것이라는 것을 의심치 않기에 이 글에 어떤 문제의 데이터 셋이 들어 있는지만 간단히 소개를 하려고 합니다.
문장 주제 분류(Topic classification)
뉴스 헤드라인에서 정치, 경제, 사회, 문화, 세계, IT/과학, 스포츠 등의 주제를 분류하는 문제입니다.
문장 유사도(Semantic Textual Similarity)
문장 두 개가 주어졌을 때, 의미가 비슷한지 아닌지 파악하는 문제입니다. 에어비엔비 리뷰, 뉴스 문장, 스마트 홈 기기의 대화 등의 도메인의 데이터이 제공된다고 합니다.
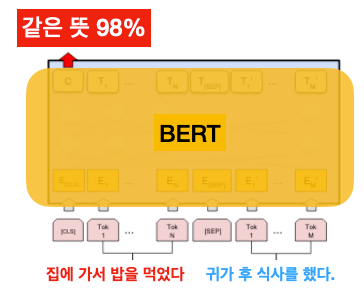
자연어 추론(Natural Language Inference)
근거(premise)가 주어졌을 때 가설(hypothesis)이 사실인지 아닌지 추론하는 문제입니다.
근거: 카카오톡을 통해 영희에게 사진을 보냈다.
가설: 영희는 스마트폰을 가지고 있다.
이처럼 근거를 보면 가설이 사실이라고 볼 수 있겠죠. 물론 카카오톡이 스마트폰 앱이라는 지식이 필요하기 때문에, 쉽지만은 않은 문제입니다.
개체명 인식(Named Entity Recognition)
NER은 문장에서 사람, 장소, 단체의 이름. 시간, 돈/무게 등 각종 수량 언어들을 뽑아내는 문제입니다.

관계 추출(Relation Extraction)
문장에 나타나는 개체(entity)의 관계를 추론하는 문제입니다.
"세종대왕은 한글을 창제하였다." => 세종대왕 / 한글 (발명가 / 발명품)
"손흥민은 영국에 살고 있다." => 손흥민 / 영국 (거주자 / 거주지)
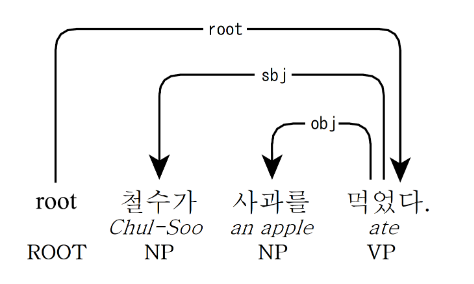
의존 구문 분석(Dependency Parsing)
문장의 의존 구조를 예측하는 문제입니다. 문법적인 분석할때 쓰이는데 다음에 기회가 되면 따로 다루어보도록 하겠습니다.
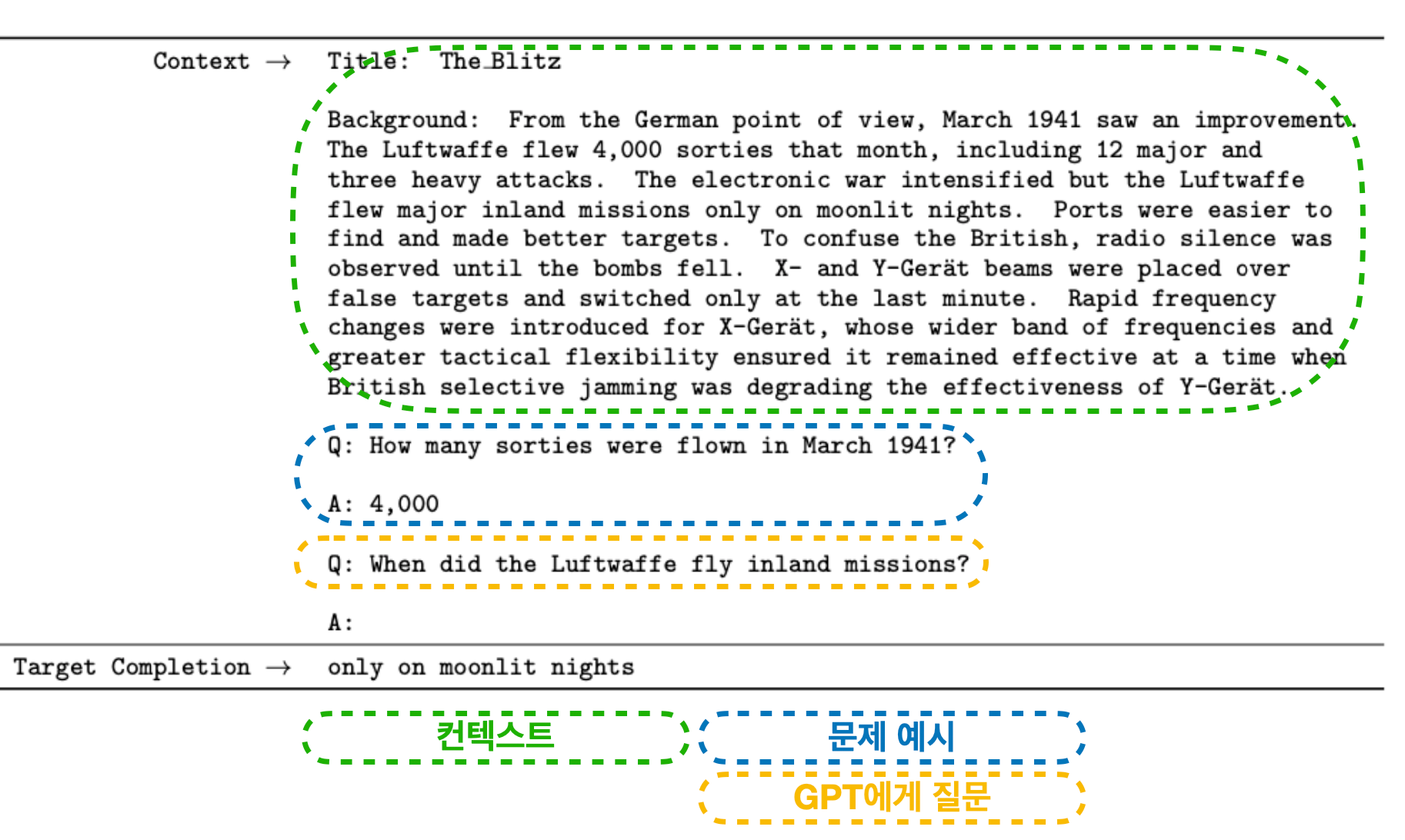
독해 (Machine Reading Comprehension)
본문 - 질문이 주어졌을 때, 답을 찾는 문제입니다. 수능 언어 영역 문제와 비슷한데요. 객관식, 서술형 등 여러 가지 방식이 있는데, 본문에서 질문에 답할 수 있는 단어들을 찾는 형태로 만들어졌다고 합니다.
목적형 대화 트래킹(Dialogue State Tracking)
대화 시스템에서 각 턴에서 유저의 요청 / 유저가 준 정보를 key-value로 바꾸는 것을 대화 상태(dialogue state)라고 합니다. 일종의 정보 추출(information extraction)인데요. 호텔, 레스토랑, 관광정보, 택시, 지하철 총 5가지 상황 도메인을 다루었다고 합니다.
더 자세한 내용은 논문, 리더보드 웹사이트, 깃허브 참고하시길 바랍니다.
오늘은 벤치마크 데이터 셋에 대해서 알아보았습니다. 여러분들은 연구에 어떤 벤치마크를 사용하고 계신가요? 업계라면 조직 내에서 벤치마크는 어떻게 활용하고 계신가요? KLUE에 작업을 하고 계신 분들이 계신가요? 있다면 댓글로 알려주세요.
앞으로도 이러한 훌륭한 NLP 데이터 연구가 많아졌으면 좋겠습니다. 데이터 관련 연구는 주목을 덜 받기 마련이거든요. 하지만 항상 머신러닝 연구/개발은 데이터에서 시작된다는 점 기억해두세요.

REFERENCE
- Moritz Hardt and Benjamin Recht, Patterns, Predictions, and Actions: A story about machine learning
- Bowman & Dahl, 2021, What Will it Take to Fix Benchmarking in Natural Language Understanding?, NAACL 2021
- KLUE: Korean Language Understanding Evaluation



